



De una latencia de varios días a insights casi en tiempo real: la actualización del pipeline de datos de Figma




Tras un crecimiento exponencial de usuarios y datos, las tareas diarias de sincronización empezaron a tardar horas o incluso días en completarse. A continuación, te explicamos cómo la reconstrucción de un pipeline de datos redujo la latencia a casi tiempo real.
Compartir De una latencia de varios días a insights casi en tiempo real: la actualización del pipeline de datos de Figma
Ilustraciones de Cynthia Alfonso
Figma ha crecido rápidamente en los últimos cinco años, incluyendo el lanzamiento de FigJam en 2021, Dev Mode en 2023, Figma Make en 2025, y la localización completa para atender a los mercados brasileño, japonés, español y coreano, pero ese crecimiento conlleva desafíos. A medida que nuestra base de usuarios se ha ampliado, también ha crecido el volumen y la complejidad de los datos que nuestra plataforma genera cada día.
El año pasado, compartimos la historia interna de cómo nuestro equipo de bases de datos escaló horizontalmente nuestras bases de datos relacionales en línea. Pero nuestro sistema de sincronización heredado, responsable de transferir datos de nuestras bases de datos en línea a nuestro almacén analítico, que alimenta insights empresariales críticos, incluidos los KPI más importantes de la empresa, tenía dificultades para mantenerse al día.

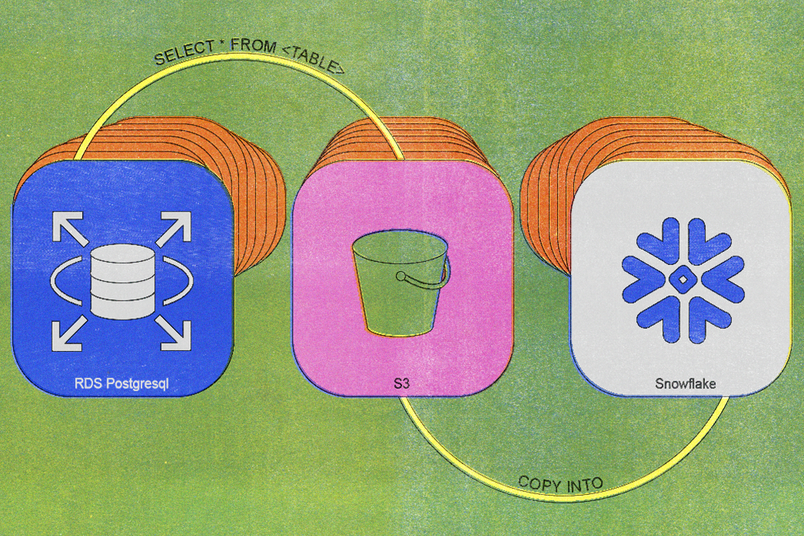
Creamos nuestro primer proceso de sincronización heredado en 2020, y la arquitectura era sencilla: una tarea cron diaria ejecutaba una simple consulta SELECT * FROM <TABLE>, cargaba los datos resultantes en S3 e importaba esos datos a Snowflake.
Al principio, esto funcionaba bien. Sin embargo, a medida que las tablas aumentaban de tamaño y se realizaban más inserciones, las limitaciones del sistema se hicieron evidentes. En 2023, las tareas de sincronización diarias tardaban alrededor de seis horas en completarse y teníamos que mantener réplicas de bases de datos adicionales para dar soporte a las exportaciones diarias. Nuestras tablas más grandes experimentaban tiempos de sincronización de varios días o más.
Con el tiempo, se hizo casi imposible sincronizar nuestros datos en un plazo razonable, lo que dificultó enormemente nuestra capacidad para analizar los datos y tomar decisiones informadas.
Evaluamos tres soluciones:
- Mantener nuestro proceso de sincronización heredado: esto se volvió rápidamente insostenible, debido tanto a los retrasos en la sincronización como al hecho de que mantener réplicas adicionales de la base de datos generaba millones de dólares en costes innecesarios cada año.
- Agregar paralelismo como una solución rápida: consideramos agregar paralelismo, lo que habría permitido que el proceso de sincronización realizara operaciones de forma simultánea, pero esto resultó no ser escalable.
- Revisar por completo el proceso de sincronización de datos: esto requeriría una mayor inversión durante un periodo de tiempo más largo, pero sería el enfoque más escalable y el que más probabilidades tendría de perdurar a medida que Figma sigue creciendo.
La sincronización incremental es una técnica de pipeline de datos diseñada para mantener las bases de datos analíticas actualizadas de manera eficiente capturando y aplicando solo los cambios recientes de la base de datos de origen, en lugar de transferir repetidamente conjuntos de datos completos. Esto ahorra el tiempo de transferencia de datos y el uso de recursos.
Al analizar las opciones, nuestra elección quedó clara: cambiamos nuestro enfoque hacia el largo plazo y comenzamos a trabajar en la sincronización incremental, una solución que prometía resultados sostenibles y eficientes.
Comprar vs. crear
Para que funcione, la sincronización incremental requiere compatibilidad con instantáneas de tablas de bases de datos, flujos de captura de datos modificados (CDC) y fusión incremental. Cuanto más analizábamos el potencial de la sincronización incremental, más nos dábamos cuenta de que tendríamos que crearla nosotros mismos. Consideramos la posibilidad de comprar una solución integral patentada, pero ninguna opción satisfacía nuestras necesidades en términos de flexibilidad, costo y escala.
Flexibilidad: muchas de las herramientas genéricas compatibles con SQL que encontramos no utilizaban de manera eficaz las capacidades específicas del proveedor. Las API de Amazon Relational Database Service (RDS) para PostgreSQL, por ejemplo, nos habrían permitido crear instantáneas directamente sin la sobrecarga que supone mantener una réplica de base de datos independiente, pero las opciones genéricas no aprovechaban esta ventaja. Si optáramos por una solución de proveedor, no tendríamos la flexibilidad necesaria para optimizar nuestro flujo de trabajo con la tecnología que ya tenemos.
Costo: muchas opciones también habrían supuesto un costo adicional significativo a nuestra escala. Cuando calculamos el precio de nuestras opciones, estimamos que las soluciones propietarias costarían entre cinco y diez veces más que una solución interna.
Escalabilidad: el costo podría haber valido la pena si esas herramientas fueran escalables, pero descubrimos que muchas de ellas no lo eran lo suficientemente para nuestras necesidades actuales y futuras. Creamos nuestro proceso de sincronización heredado en 2020, y Figma sigue creciendo. Al desarrollarlo internamente, nos aseguramos de poder innovar rápidamente en respuesta a necesidades futuras.
Creación y combinación de componentes de bajo nivel
Al crear un pipeline personalizado, pudimos encontrar y combinar componentes de bajo nivel, ya fueran servicios de código abierto o gestionados, que se alineaban con nuestros requisitos exactos de infraestructura (y la experiencia de nuestro equipo).
Para las instantáneas, utilizamos Amazon RDS, que puede exportar a S3 para copias iniciales de tablas. Para CDC, utilizamos Kafka Connect, que ofrece transmisión eficiente una vez integrado con un conector Snowflake y alojado en Amazon Managed Streaming for Apache Kafka (MSK). Para la fusión incremental, implementamos lógica personalizada para fusionar a través de procedimientos almacenados de Snowflake y procesos automáticos mediante tareas de Snowflake.
Creación de una nueva arquitectura de pipeline
Con cada nuevo proyecto, esbozamos los principios de diseño que guían el trabajo, dando forma a nuestros objetivos y decisiones. Para este proyecto, definimos cuatro principios:
- Latencia: reducir el tiempo para sincronizar datos de extremo a extremo.
- Costo: reducir los costos y mantenerlos bajos aunque seguimos creciendo.
- Cumplimiento:: mantener el cumplimiento de todas las normas reglamentarias pertinentes en materia de datos.
- Integridad de datos: utilizar flujos de trabajo que garanticen que los datos sigan siendo precisos, completos, consistentes y confiables a lo largo de todo el ciclo de vida.

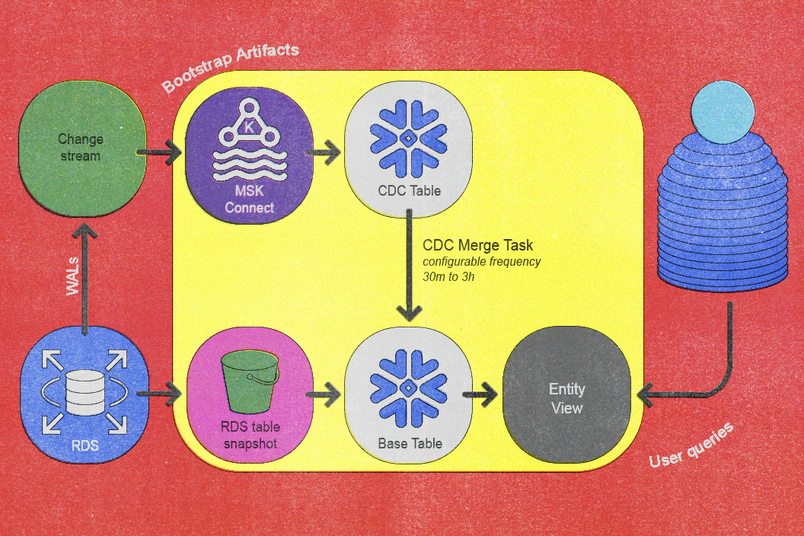
En última instancia, estos principios se tradujeron en un pipeline de datos rediseñado que logra una sincronización incremental a través de dos flujos de trabajo fundamentales: un flujo de trabajo de bootstrap y un flujo de trabajo de validación. El flujo de trabajo de bootstrap integra nuevas tablas en el pipeline, y el flujo de trabajo de validación verifica la exactitud de los datos a medida que estos fluyen dentro del pipeline. Juntos, estos dos flujos de trabajo garantizan que los datos fluyan de manera eficiente y se mantengan lo más consistentes y correctos posible.
Flujo de trabajo de bootstrap
Nuestro proceso de incorporación para integrar nuevas tablas en el pipeline de sincronización consta de los siguientes pasos automatizados y claramente definidos:
- El servicio de CDC existente captura la nueva tabla de Postgres y publica eventos en los temas por tabla de Kafka. Automatizamos este paso utilizando nuestro servicio CDC interno existente y lo integramos con la topología del sistema de base de datos.
- Transferimos la última instantánea diaria de la base de datos a S3 utilizando el proceso de exportación de instantáneas de Amazon RDS (que puede ser largo dependiendo del tamaño de la tabla).
- Una vez que la instantánea se exporta correctamente a S3, la consulta
COPY INTO <table>de Snowflake importa los datos de S3 a las tablas base dedicadas por entidad de Snowflake. - Un conector Snowflake Sink dentro de MSK Connect transmite el contenido de los temas de Kafka a las tablas CDC por entidad de Snowflake, lo que garantiza que el desplazamiento inicial de Kafka sea anterior a la marca de tiempo de la instantánea.
- Programamos una tarea de Snowflake para ejecutar periódicamente un procedimiento almacenado
MERGEpersonalizado que desarrollamos. - Cuando la sincronización se pone al día con los cambios recientes, creamos una vista ligera sobre la tabla base para facilitar las consultas de los usuarios, lo que completa la incorporación.
Implementamos una capacidad de volver a ejecutar el bootstrap sin tiempo de inactividad, que es crucial para gestionar eventos como la evolución del esquema. Para hacer esto, versionamos todos los artefactos de bootstrap excepto la vista final orientada al usuario, lo que permite ejecutar el bootstrap en paralelo sin interrumpir las operaciones en vivo. La promoción a la nueva versión se realiza de forma fluida mediante un paso de actualización de vista atómica.
Flujo de trabajo de validación
A pesar de sus sólidos diseños, los pipelines de datos corren inevitablemente el riesgo de sufrir daños en los datos debido a fallas parciales, componentes mal configurados, errores de software o anomalías inesperadas en los datos de origen. Los problemas pueden surgir en varios puntos, desde la exportación de instantáneas y la captura de eventos CDC hasta las fusiones incrementales, y pueden causar inconsistencias silenciosas en los datos o resultados analíticos incorrectos si no se controlan.
Por lo tanto, otro aspecto crítico de la arquitectura es un sólido flujo de trabajo de validación dedicado a verificar la exactitud de los datos, que funciona de la siguiente manera:
- Clona la tabla base activa, que designamos como fuente.
- Ejecuta el flujo de trabajo de bootstrap, que hemos configurado explícitamente para exportar las tablas base y de CDC a un esquema temporal, etiquetado como destino. Esto se ejecuta sin iniciar fusiones automatizadas.
- Alinea las tablas base de origen y destino en posiciones idénticas en el tiempo utilizando los datos CDC exportados para garantizar la consistencia.
- Realiza comparaciones precisas, celda por celda, entre las tablas de origen y destino.
- Genera resultados detallados a partir de estas comparaciones e integra los resultados en nuestros sistemas de supervisión y alerta.
Esta validación rigurosa, a nivel de celda y conforme a los estándares del CDC, proporciona una confianza absoluta en la integridad de los datos, lo que mejora sustancialmente la confiabilidad antes y después del lanzamiento del servicio.
Invertir en automatización
El éxito en este caso no habría sido posible sin la automatización. El pipeline que creamos requería una amplia coordinación entre numerosas llamadas en red y dependencias, y necesitábamos tanto automatización ad hoc como programada para que todo funcionara correctamente.
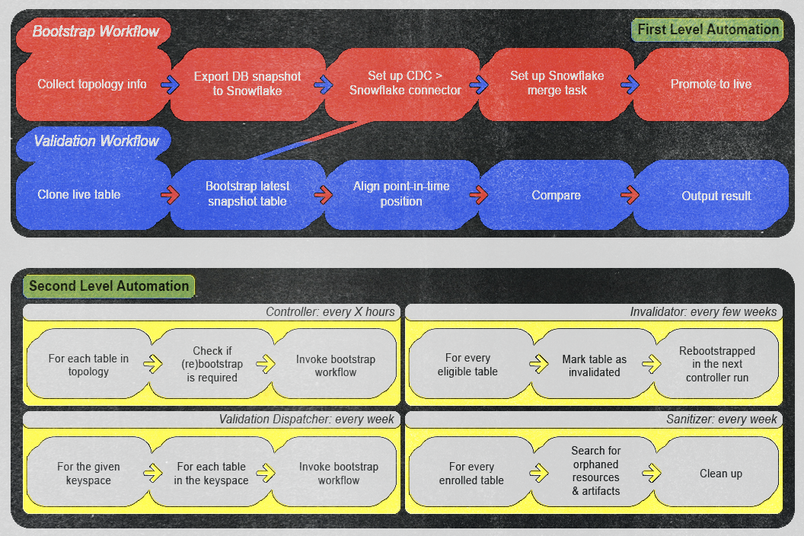
Con AWS Step Functions, organizamos nuestra automatización en dos categorías:
Automatización de primer nivel: esta categoría incluye flujos de trabajo que podemos activar de forma manual y ad hoc. Los diseñamos para ejecutar procesos de bootstrap o validación proporcionando únicamente el nombre de la entidad. Una vez ejecutados, estos flujos de trabajo no requieren intervención manual a menos que la supervisión genere una alerta. Nos aseguramos de que las alertas sean lo suficientemente fuertes como para provocar una acción inmediata por parte del operador, ya sea un error real en el proceso o un falso positivo en la lógica de validación, y proporcionamos medidas claras para evitar que se repita y mantener una alta eficiencia y confiabilidad operativa.
Automatización de segundo nivel: esta categoría incluye flujos de trabajo que diseñamos para invocar automatizaciones de primer nivel basadas en condiciones y horarios específicos. El primer nivel realiza el trabajo pesado y el segundo nivel verifica automáticamente los estados actuales para ver si necesitamos activar una automatización de primer nivel. Los ejemplos incluyen:
- Un flujo de trabajo de control verifica cada pocas horas si hay nuevas entidades para su incorporación o para volver a ejecutar el bootstrap.
- Un flujo de trabajo de validación inicia automáticamente flujos de trabajo de validación para cada tabla semanalmente.
- Un flujo de trabajo de invalidación realiza operaciones de bootstrap semanales en cada tabla para garantizar la integridad de los datos.
- Un flujo de trabajo de limpieza realiza periódicamente la depuración de artefactos potencialmente huérfanos cada semana, manteniendo un entorno ordenado y eficiente.

Adoptamos un enfoque agresivo para las pruebas: una rigurosa rutina de automatización en nuestro entorno de preproducción vuelve a ejecutar automáticamente el bootstrap de todas las tablas cada semana para simular y detectar de manera proactiva posibles problemas. Esto resultó muy útil cuando identificamos un modo de falla grave tan solo una semana después de comenzar las pruebas. Este problema habría provocado una interrupción en todo el sitio que habría durado al menos veinte minutos si hubiera llegado a la fase de producción. Al detectarlo a tiempo, garantizamos la estabilidad durante las implementaciones de producción reales.
Casos como este reforzaron nuestra convicción de que la automatización total tenía que ser nuestro objetivo principal. Incluso cuando algunos flujos de trabajo parecían difíciles o arriesgados de automatizar por completo, avanzamos progresivamente hacia la automatización total, mientras implementábamos la automatización parcial de forma provisional. Este enfoque nos permitió mejorar constantemente la fiabilidad del sistema y reducir los gastos generales operativos con el tiempo.
Las operaciones se han mantenido sin interrupciones y sin incidentes importantes durante y después del lanzamiento.
Nuevas funciones para obtener mejores insights en tiempo real
A medida que realizamos la transición a esta nueva arquitectura, nuestras capacidades mejoradas de flexibilidad y automatización nos brindaron oportunidades para desarrollar nuevas funciones. Tres mejoras clave optimizaron significativamente nuestra experiencia de usuario y la productividad de los desarrolladores.
Actualización configurable
Basándonos en el feedback de los usuarios finales, establecimos la frecuencia de fusión predeterminada a cada tres horas para poder equilibrar la actualización base de todas las entidades con los costos de cómputo de Snowflake. Además, introdujimos ajustes configurables para las tablas que requieren actualizaciones más frecuentes. Por ejemplo, nuestro pipeline de facturación se benefició significativamente de ajustes de media hora, lo que redujo considerablemente la latencia total del pipeline de extremo a extremo.
Sincronización bajo demanda
Gracias a nuestro sistema de cola de trabajos de fusión, podemos activar fusiones de forma segura en cualquier momento. Esta renovada seguridad nos permitió introducir una herramienta CLI fácil de utilizar que permite la sincronización manual e inmediata de datos fuera del horario automatizado habitual. Esto garantiza el acceso oportuno a datos actualizados de la base de datos en línea en Snowflake siempre que sea necesario.
Inspección de datos de CDC en Snowflake
Dado que los datos de CDC ya se habían importado a Snowflake para uso interno, los pusimos a disposición de los usuarios finales interesados en obtener insights más detallados que exploraran la secuencia de cambios que condujeron al estado de una entidad, y no solo el estado actual de dicha entidad. Durante la respuesta a incidentes, esta función proporciona un entorno seguro sin conexión para depurar actividades inesperadas de escritura en la base de datos. Por ejemplo, los desarrolladores pueden realizar consultas como "recuperar todos los eventos de inserción/actualización/eliminación de correos electrónicos de los usuarios de un equipo específico durante la última semana". Al utilizar también nuestra función de sincronización bajo demanda, los desarrolladores pueden consultar estos datos en Snowflake casi en tiempo real. Para cumplir con las políticas de retención de datos y evitar un crecimiento indefinido del almacenamiento, los datos de CDC se eliminan automáticamente después de un período predefinido.
Resultados
Este proyecto requirió una importante inversión de tiempo, esfuerzo y recursos, pero el trabajo dio sus frutos y los resultados superaron nuestras expectativas.
Mejora en la actualización de los datos
Mejoramos considerablemente la actualización de los datos. Anteriormente, los datos solían tener 30 horas o más de antigüedad. Ahora, los datos tienen tres horas o menos de antigüedad, y los usuarios tienen la flexibilidad de configurar la actualización en cuestión de minutos.
Rendimiento escalable
Ahora, este pipeline maneja de forma fiable tablas que son más de diez veces más grandes que antes, con un rendimiento constante y predecible a medida que Figma sigue creciendo.
Productividad del desarrollador
Las nuevas herramientas siempre plantean la posibilidad de interrumpir el flujo de trabajo, por lo que generamos confianza en nuestro equipo con entrevista para identificar sus necesidades e integrando el pipeline con sistemas que nuestro equipo conocía bien.
Una vez completado el trabajo, pudimos demostrar un aumento significativo de la productividad de los desarrolladores gracias a la reducción de los gastos operativos y al acceso casi en tiempo real a los datos en línea dentro del almacén de analítica.
Ahora los desarrolladores pueden consultar de forma segura tanto el estado actual como el historial de cambios, actualizados cada pocos minutos, y así responder más rápido a las incidencias, realizar implementaciones más seguras y obtener insights más detallados.
Rentabilidad
Al inicio de la implementación, priorizamos el soporte para bases de datos fragmentadas horizontalmente. Este soporte ofreció un alto retorno de la inversión, ya que las bases de datos fragmentadas horizontalmente tenían menos tablas, pero utilizaban más máquinas de bases de datos, cada una con su propia réplica por lotes. Ahora, este pipeline genera un ahorro anual de varios millones de dólares al optimizar de forma inteligente la infraestructura y la utilización de los recursos, eliminar el procesamiento redundante y adaptarse perfectamente al crecimiento del negocio.
Oportunidades futuras
Nuestra nueva arquitectura sienta las bases para varias oportunidades interesantes que permitirán mejorar y ampliar aún más el pipeline de datos.
- Incorporación totalmente automatizada: actualmente, la incorporación requiere una solicitud de extracción para agregar tablas a una lista de permitidos, lo que genera fricciones en el proceso de incorporación. Integrar nuestra topología de base de datos directamente en el pipeline automatizaría por completo la incorporación de tablas, optimizando la experiencia del desarrollador y reduciendo la sobrecarga manual.
- Compatibilidad con tablas en momentos puntuales: podemos ofrecer la posibilidad de consultar el estado de las tablas en cualquier momento dentro de nuestro periodo de retención de CDC definido utilizando nuestros datos de CDC. Implementar esta función mejoraría significativamente las capacidades de depuración, la respuesta a incidentes y la flexibilidad analítica.
- Modelos posteriores actualizados de forma incremental: muchos de nuestros modelos analíticos posteriores siguen creándose mediante procesos por lotes tradicionales. Nuestro nuevo pipeline nos permitiría actualizarlos de forma incremental, mejorando dramáticamente su eficiencia y reduciendo la latencia en todo el flujo de trabajo analítico.
Esta ambiciosa transformación fue posible gracias a la increíble dedicación y esfuerzo de los miembros actuales y anteriores del equipo de infraestructura de datos de Figma: Amadeo Casas, Alex Tian, Brandon Choi, Carter Bian, David Mah, Dorothy Chen, Ebuka Akubilo, Jimmy Xie, Krish Chainani, Merry Song, Michael Wu, Peng Wang, Raunak Agnihotri, Santosh Muthukrishnan, Xinxin Dai y Zubair Saiyed.
También queremos expresar nuestro especial reconocimiento y agradecimiento a nuestros equipos de socios colaboradores: Asheesh Laroia, Dylan Visher, Gordon Yoon, Gustavo Angulo Mezerhane, Langston Dziko, Ping-Min Lin, Sammy Steele, Sean Rice y Yazad Khambata.

¡Estamos contratando ingenieros! Obtén más información sobre la vida en Figma yexplora nuestras vacantes.