



複数日にわたるレイテンシーからほぼリアルタイムのインサイトへ: Figmaのデータパイプラインのアップグレード




ユーザーとデータが指数関数的に増加したため、毎日の同期タスクは完了するのに数時間、あるいは数日かかるようになりました。データパイプラインを再構築することで、レイテンシーをほぼリアルタイムにまで減少させた方法を紹介します。
複数日にわたるレイテンシーからほぼリアルタイムのインサイトへ: Figmaのデータパイプラインのアップグレードを共有
イラスト: Cynthia Alfonso
Figmaは過去5年間で急成長しました。2021年のFigJamの発売、2023年のDev Mode、2025年のFigma Makeはその一端です。ブラジル、日本、スペイン、韓国の市場に対応する完全なローカリゼーションも実施しました。しかし、その成長には課題も伴います。ユーザーベースが拡大するにつれて、プラットフォームが毎日生成するデータのボリュームと複雑さも増しています。
昨年、私たちはデータベースチームがオンラインリレーショナルデータベースを水平スケーリングした内部ストーリーを紹介しました。しかし、オンラインデータベースから分析用データウェアハウスにデータを転送し、企業の上層部のKPIを含む重要なビジネスインサイトを支えるレガシー同期システムは、維持するのが困難でした。

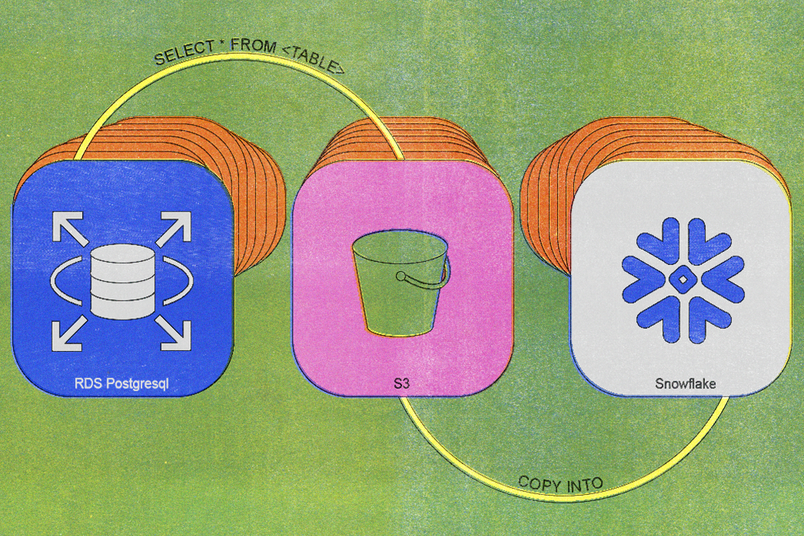
当社の最初のレガシー同期プロセスは2020年に構築され、そのアーキテクチャは単純でした。毎日のcronジョブがシンプルなSELECT * FROM <TABLE>クエリを実行し、結果のデータをS3にアップロードし、そのデータをSnowflakeにインポートしました。
最初はうまく機能していました。しかし、テーブルが大きくなり、挿入が増えるにつれて、システムの限界が明らかになりました。2023年までには、日々の同期作業に約6時間かかるようになり、日々のエクスポートをサポートするために追加のデータベースレプリカを維持する必要がありました。最大規模のテーブルでは、調整時間が数日以上かかることがありました。
最終的に、データを合理的な時間枠内で同期することがほぼ不可能になり、データを分析して情報に基づいた意思決定をすることが非常に困難になりました。
私たちは3つのソリューションを評価しました。
- レガシー調整プロセスを維持する: これはすぐに持続不可能になりました。理由として、調整が遅れることと、余分なデータベースレプリカの維持が毎年数百万ドルの無駄なコストを引き起こしていることがあります。
- 並列化を迅速な解決策として追加する: 同期プロセスが並行して操作を行えるように並列化を追加することを検討しましたが、これはスケーラブルではないことが判明しました。
- データ同期プロセスを完全に見直す: これはより長期的な大きな投資となるでしょうが、最もスケーラブルなアプローチであり、Figmaが成長を続ける中でも最も持続可能な方法です。
増分同期は、分析データベースを効率的に最新に保つためのデータパイプライン技術で、ソースデータベースからの最近の変更のみをキャプチャして適用することで、データセット全体を繰り返し転送しなくてすむようになります。これにより、データ転送時間とリソース使用率が大幅に削減されます。
選択肢を検討した結果、私たちの選択は明確になりました。長期的な視点に焦点を移し、持続可能で効率的な成果を約束する解決策である「増分同期」に取り組み始めたのです。
購入と構築
増分同期を機能させるためには、データベーステーブルのスナップショット、データ変更キャプチャ (CDC) ストリーム、および増分マージのサポートが必要です。増分同期の可能性を探るにつれ、自分たち自身で構築しなければならないことがわかりました。専有のエンドツーエンドソリューションを購入することも考えましたが、柔軟性、コスト、規模の面で私たちのニーズを満たすオプションはありませんでした。
柔軟性: 私たちが見つけた多くの一般的なSQL互換ツールは、ベンダー固有の機能を効果的に利用していませんでした。例えば、Amazon Relational Database Service (RDS) for PostgreSQLのAPIでは、別のデータベースレプリカを維持するオーバーヘッドなしにスナップショットを直接生成することが可能だったはずですが、一般的なオプションではこれを利用できませんでした。ベンダーソリューションを選択した場合、私たちは既存の技術に基づいたワークフローを柔軟に最適化することはできなかったでしょう。
コスト: 多くのオプションでは、当社の規模ではかなりの追加料金がかかる可能性があります。オプションの価格を見積もったところ、独自ソリューションは自社製ソリューションの5倍から10倍の費用がかかると予測されました。
スケール: これらのツールがスケールできるならばコストは価値があったかもしれませんが、実際はその多くが現在のニーズや成長のニーズにとって十分にスケーラブルでないことがわかりました。私たちのレガシーな同期プロセスが構築されたのは2020年ですが、Figmaはまだ成長しています。社内で構築することにより、将来のニーズにあわせて迅速にイノベーションできるようにします。
下位レベルのコンポーネントを構築し、組み合わせる
カスタムパイプラインを構築することにより、正確なインフラ要件 (およびチームの専門知識) に合致する下位レベルのコンポーネント (オープンソースまたはマネージドサービス) を見つけて組み合わせることができました。
スナップショットの場合、Amazon RDSを使用しており、初期テーブルコピーのためにS3へのエクスポートが可能です。CDCについてはKafka Connectを使用しています。これは、Snowflakeコネクターに統合され、Amazon Managed Streaming for Apache Kafka (MSK) でホストされると、効率的なストリーミングを提供します。増分マージの場合、Snowflakeストアドプロシージャを通じてカスタムマージロジックを実装し、Snowflakeタスクを介してプロセスを自動化しました。
新しいパイプラインアーキテクチャを構築する
新しいプロジェクトごとに、私たちは作業の基準となるデザインの原則を作成し、目標と決定を形成します。このプロジェクトのために、私たちは4つの原則を定義しました。
- レイテンシー: エンドツーエンドでデータを同期する時間を短縮します。
- コスト: コストを削減します。成長を続けても、コストは低く抑えます。
- コンプライアンス: 関連するすべてのデータ規制基準を遵守します。
- データの整合性: データがライフサイクル全体を通じて正確で、完全で、一貫性があり、信頼できる状態を保つワークフローを使用します。

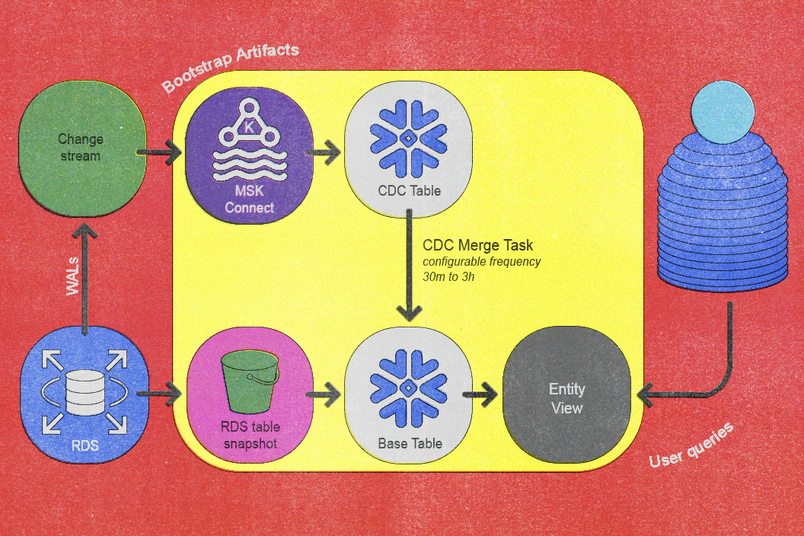
最終的に、これらの原則は、2つの基本的なワークフロー、つまりブートストラップワークフローと検証ワークフローにより、再構築されたデータパイプラインに変換され、増分同期を実現できるようになります。ブートストラップワークフローは新しいテーブルをパイプラインに統合し、検証ワークフローはデータがパイプラインにフローする際のデータの正確性を確認します。これら2つのワークフローを合わせて使用することにより、データの効率的なフローを確保し、可能な限り一貫性と正確性を保持します。
ブートストラップワークフロー
同期パイプラインに新しいテーブルを統合するためのオンボーディングプロセスは、次のステップで構成されています。これらのステップは自動化され、また明確に定義されています。
- 既存のCDCサービスがPostgresから新しいテーブルをキャプチャし、Kafkaのテーブルごとのトピックにイベントを公開します。Figmaではこのステップを既存の社内CDCサービスを使用して自動化し、データベースシステムのトポロジーに統合しました。
- 最新のデイリーデータベーススナップショットをAmazon RDSのスナップショットエクスポートプロセスを使用してS3に転送します (テーブルのサイズによっては時間がかかる場合があります)。
- スナップショットがS3に正常にエクスポートされると、Snowflakeの
COPY INTO <table>クエリにより、データがS3からSnowflakeのエンティティごとの専用基本テーブルにインポートされます。 - MSK Connect内のSnowflake Sink Connectorは、Kafkaトピックの内容をSnowflakeのエンティティごとのCDCテーブルにストリーミングし、Kafkaの開始オフセットがスナップショットのタイムスタンプよりも前であることを確認します。
- 私たちは、開発したカスタム
MERGEストアドプロシージャを定期的に実行するように、Snowflakeタスクをスケジュールします。 - 同期で最近の変更に十分に追いつくと、ベーステーブルに基づき軽量なビューを作成し、ユーザーが簡単にクエリできるようにします。これにより、オンボーディングが完了します。
ゼロダウンタイムの再ブートストラップ機能を実装しました。これは、スキーマの進化のようなイベントを管理する上で重要です。これを行うために、最終的なユーザー向けビューを除くすべてのブートストラップアーティファクトをバージョン管理しました。これにより、実稼働オペレーションを乱すことなく、並行してブートストラップを行うことが可能です。新しいバージョンへの昇格は、アトミックなビュー更新ステップによりシームレスに行われます。
検証ワークフロー
強固にデザインされていても、データパイプラインは部分的な失敗、コンポーネントの誤設定、ソフトウェアのバグ、予期しないソースデータの異常が原因でデータが破損するリスクがあります。問題は、スナップショットのエクスポートやCDCイベントのキャプチャ、増分マージなど、さまざまなポイントで発生する可能性があります。問題が確認されないままだと、データの不一致や誤った分析結果を引き起こす可能性があります。
したがって、アーキテクチャのもう一つの重要な要素として、データの正確性を検証するために専用された強固な検証ワークフローがあります。これは以下のように動作します。
- 稼働中のベーステーブルを複製し、それをソースとして指定します。
- ブートストラップワークフローを実行します。このワークフローは、ターゲットとしてラベル付けされた一時的なスキーマにベーステーブルとCDCテーブルにエクスポートするよう明示的に構成されています。これは自動マージを開始せずに実行されます。
- エクスポートされたCDCデータを使用して、ソースとターゲットのベーステーブルを同じ時点の位置に揃えることで、一貫性を確保します。
- ソーステーブルとターゲットテーブルの間で精密なセル間の比較を行います。
- これらの比較から詳細な出力を生成し、その結果を監視およびアラートシステムに統合します。
この厳格なセルレベルでのCDC対応検証により、データの完全性への信頼性が絶対的なものになり、サービス開始前後の信頼性が大幅に向上します。
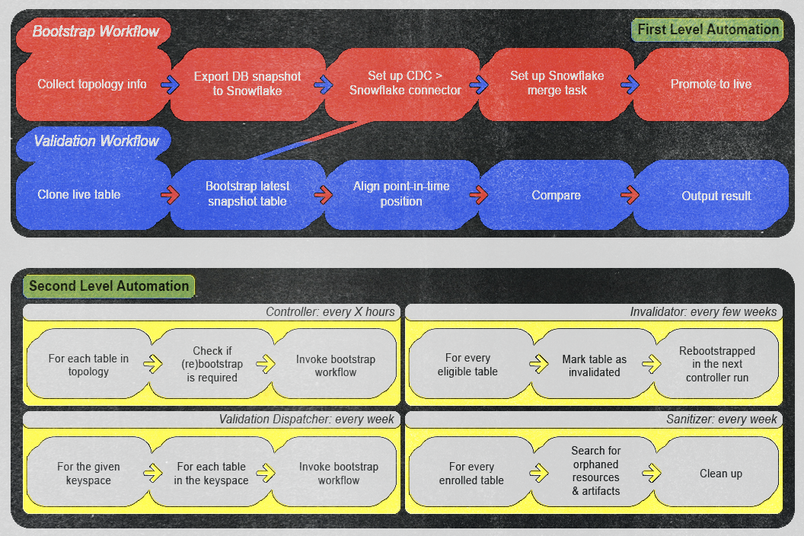
自動化への投資
ここでの成功は自動化なしには実現できませんでした。私たちが構築したパイプラインは、多数のネットワークコールや依存関係をまたいで広範囲にわたる調整が必要で、すべてを実現するためにはアドホックな自動化とスケジュールされた自動化の両方が必要でした。
私たちはAWS Step Functionsを使用して、自動化を2つのカテゴリに整理しました。
第1レベルの自動化: このカテゴリーには、手動およびアドホックでトリガーできるワークフローが含まれます。私たちは、エンティティ名を指定するだけでブートストラップまたは検証プロセスを実行するように設計しました。一度実行されると、これらのワークフローは、監視によりアラートが発生しない限り、手動での介入を必要としません。私たちは、アラートが十分に大きく、即座にオペレーターの行動を促すものであることを確認しました。これはパイプライン内の実際のバグであるか、検証ロジックにおける偽陽性であるかに関わらず同様でした。また、再発を防止し、高い運用効率と信頼性を維持するための明確な行動項目を指定しました。
第2レベルの自動化: このカテゴリーには、特定の条件とスケジュールに基づいて第1レベルの自動化を実行するために設計したワークフローが含まれます。第1レベルでは重労働を行います。第2レベルでは、現在の状態を自動的にチェックして、第1レベルの自動化をトリガーする必要があるかどうかを確認します。例として以下のようなものがあります。
- コントローラーのワークフローは、オンボーディングまたは再ブートストラップのために利用可能な新しいエンティティを数時間ごとに定期的にチェックします。
- 検証ディスパッチャーワークフローは、毎週各テーブルの検証ワークフローを自動的に開始します。
- 無効化ワークフローは、データの整合性を確保するために、各テーブルで毎週リブートストラップ操作を実行します。
- サニタイザーワークフローによって、毎週潜在的に孤立しているアーティファクトを定期的にクリーンアップし、整然とした効率的な環境を維持しています。

私たちはテストに対して積極的なアプローチを取りました。ステージング環境での厳密な自動化ルーチンにより、毎週すべてのテーブルを自動的に再ブートストラップし、潜在的な問題をシミュレーションしながら事前に発見できるようにしています。これにより、テスト開始からわずか1週間で深刻な障害モードを特定できました。この問題は、実際の本番環境だった場合、サイト全体の停止を引き起こし、少なくとも20分間続いたでしょう。これを早期に発見することで、実稼働時の安定性を確保しました。
このようなケースは、完全自動化を目指すべきだという私たちの信念を後押しするものでした。ワークフローの中には、完全に自動化するのが難しい、またはリスクがあるように見えるものもありますが、完全自動化に向けて徐々に取り組み、その間に部分的な自動化を実装してきました。このアプローチにより、システムの信頼性を着実に改善し、時間をかけて運用コストを削減することができました。
運用は順調で、リリース中もリリース後も重大なインシデントは一切ありませんでした。
リアルタイムインサイトを改善する新機能
この新しいアーキテクチャに移行することで、柔軟性と自動化性能が向上し、新機能を開発できるようになりました。3つの主要な強化点により、ユーザーエクスペリエンスと開発者の生産性が大幅に向上しました。
構成可能な鮮度
エンドユーザーからのフィードバックに基づいて、すべてのエンティティの基礎となる鮮度とSnowflakeの計算コストのバランスを確保するために、デフォルトのマージ頻度の設定を3時間ごとにしました。さらに、より頻繁な更新が必要なテーブルに対して、構成可能なオーバーライドを導入しました。例えば、請求パイプラインでは、オーバーライドを30分ごとにすると、エンドツーエンドのパイプラインレイテンシーが大幅に減少しました。
オンデマンド同期
マージジョブキューシステムのおかげで、いつでも安全にマージをトリガーすることができます。これで安全性が向上したため、ユーザーフレンドリーなCLIツールを導入することができ、通常の自動スケジュール外でも手動で即座にデータを同期することが可能になりました。これにより、必要なときにSnowflakeで最新のオンラインデータベースのデータにタイムリーにアクセスできるようになります。
SnowflakeにおけるCDCデータの検査
CDCのデータはすでに内部の目的でSnowflakeにインポートされていたため、エンティティの現在の状態だけでなく、エンティティの状態に至るまでの変更の過程を探るより深いインサイトを求めるユーザーに、このデータを公開しました。この機能により、インシデント対応中に、予期しないデータベース書き込み活動をデバッグするための安全なオフライン環境を利用できます。たとえば、開発者は「過去1週間以内に、特定のチーム内のユーザーについて、すべてのメール挿入/更新/削除イベントを取得する」といったクエリを実行できます。私たちのオンデマンド同期機能を使用することで、開発者はSnowflakeでこのデータをほぼリアルタイムでクエリできます。データ保持ポリシーに準拠し、保存容量の無限の増加を防ぐために、事前指定した期間が経過した後にCDCデータは自動的に消去されます。
結果
このプロジェクトは、時間、努力、リソースを大きく投資しましたが、結果として期待を超える成果が得られました。
データの鮮度の向上
データの鮮度が劇的に改善しました。以前はデータが30時間以上前のものであることも多くありました。現在では、データは3時間以内のものであり、ユーザーは分単位で鮮度を柔軟に設定できます。
スケーラブルなパフォーマンス
このパイプラインは、以前の10倍以上の大きさのテーブルを安定的に処理し、Figmaの成長に伴い一貫した予測可能なパフォーマンスを提供します。
開発者の生産性
新しいツールは常にワークフローに混乱をもたらす可能性があるため、私たちはチームのニーズを特定するためにインタビューを行い、チームがよく知っているシステムとパイプラインを統合することで信頼性を築きました。
この作業が完了した後、運用の負担が軽減され、アナリティクスウェアハウス内でオンラインデータへのほぼリアルタイムのアクセスが可能になったため、開発者の生産性が大幅に向上しました。
開発者は現在の状態と変更履歴を安全にクエリでき、数分以内に新鮮なデータを取得できるため、迅速なインシデント対応、安全な展開、より詳細なインサイトを得ることができます。
コスト効率
実装の初期段階で、水平シャーディングされたデータベースのサポートを優先しました。このサポートにより、高い費用対効果が得られました。水平シャーディングされたデータベースではテーブルの数は少なくなりますが、利用するデータベースマシンは多くなり、そのそれぞれに独自のバッチレプリカがあるためです。このパイプラインは、インフラストラクチャとリソースの利用をインテリジェントに最適化し、冗長な処理を排除し、ビジネスの成長に伴ってシームレスに拡大することで、年間数百万ドルの節約を実現しています。
将来の機会
私たちの新しいアーキテクチャを基に、データパイプラインをさらに強化し拡張するための絶好の機会が得られます。
- 完全自動化されたオンボーディング: 現在、オンボーディングには許可リストにテーブルを追加するためのプルリクエストが必要なため、オンボーディングプロセスに摩擦が生じています。私たちのデータベーストポロジーを直接パイプラインに統合することで、テーブルのオンボーディングを完全に自動化し、開発者体験を合理化し、手作業の負担を軽減します。
- 時点単位のテーブルのサポート: CDCデータを使用して、定義したCDC保持期間内で、任意の時点の位置でテーブルの状態をクエリできるようになりました。この機能を実装することで、デバッグ能力、インシデント対応、および分析の柔軟性が大幅に向上します。
- 増分更新されたダウンストリームモデル: 多くのダウンストリーム分析モデルは、依然として従来のバッチプロセスを使用して構築されています。新しいパイプラインでは、これらを段階的に更新できるようになり、効率が大幅に向上し、ワークフロー全体でのレイテンシーが縮小されました。
この野心的な変革は、Figmaのデータインフラストラクチャチームの現メンバーと元メンバーの信じられないほどの献身と努力によって可能になりました。以下にその名前をあげます。Amadeo Casas、Alex Tian、Brandon Choi、Carter Bian、David Mah、Dorothy Chen、Ebuka Akubilo、Jimmy Xie、Krish Chainani、Merry Song、Michael Wu、Peng Wang、Raunak Agnihotri、Santosh Muthukrishnan、Xinxin Dai、Zubair Saiyed
特別な認識と感謝の意を、ご協力いただいたパートナーチームにも表します。以下にメンバーの名前をあげます。Asheesh Laroia、Dylan Visher、Gordon Yoon、Gustavo Angulo Mezerhane、Langston Dziko、Ping-Min Lin、Sammy Steele、Sean Rice、Yazad Khambata

エンジニア募集中! Figmaでの働き方について詳しくは、募集中のポストをご覧ください。