



広範囲な可視性: Figmaが機密データの露出を検出する方法



大規模なセキュリティ課題を解決するには、厳密さだけでなく創造性も必要です。機密データの露出リスクを抑えるために、FigmaではResponse Samplingを構築しました。これは軽量でリアルタイムのコントロールで、送信応答の監視やアクセスの検証を行い、製品全体での早期警告システムとして機能します。
広範囲な可視性: Figmaが機密データの露出を検出する方法を共有
イラスト: Jose Flores
プログラムによる機密データの露出を防ぐことは、セキュリティエンジニアリングにおける複雑な課題の一つです。現代の分散システムの性質上、データは複雑で、ときに予測が難しい経路をたどります。複数のサービス間、複数のシリアライズの層を通過し、存在が必ずしも明白ではないコンテキストへと入り込むことさえあります。こうした問題は、きわめて微妙な形で表面化することがあります。たとえば、エンドポイントが意図したよりも多くのデータを返したり、コードパスが古いため権限チェックが省略されたり、あるいは検証が行われずユーザーが本来アクセスすべきでないリソースを閲覧できてしまうことがあります。セキュリティの観点から見ると、これらは認証の不備や意図しないデータの過剰露出の一種であり、たとえ小さな間違いであっても、プライバシーや信頼に大きな影響を与えることになりかねません。
Figmaではこの課題に正面から取り組むため、セーフティネットであると同時に早期警戒システムとして機能する監視システムを構築する必要がありました。実稼働前のステージングの段階で露出を検知し、さらにデプロイ後も予期せぬリグレッションを継続的に監視するシステムです。これは、信頼できる精度を備え、製品のさまざまな部分にわたって価値のあるものを構築することを意味しました。
ここでは、FigmaでのResponse Samplingの構築について説明します。このシステムは、潜在的な機密データ漏洩をリアルタイムで検出するために設計されています。Response Samplingは、Figmaのサービスから送出されるデータを継続的に監視することで、Figmaのチームが問題の調査と対処を迅速に行えるようになるため、露出のリスクが減り、データ処理を確実にできるようになります。
Figmaではこの問題にプラットフォームセキュリティの考え方で取り組みました。アプリケーションサーフェスをインフラストラクチャのように扱い、その上に継続的な監視と検出コントロールを重ねました。通常は下位レベルシステムに使われる技術をアプリケーションレイヤーに応用することにより、開発を遅らせることなく、データが製品内でどのように動くのかを継続的に監視することができました。
問題の特定: 隠れた露出の認識
Figmaでは、権限と認証を重要視しています。Figmaでは長年にわたり、精度の高い認証フレームワークであるPermissionsV2のような強固な予防制御に投資してきました。また、ネガティブユニットテストを通じた継続的なテスト、ステージングおよび実稼働環境でのエンドツーエンドテスト、継続的なセキュリティレビュープログラム (バグバウンティプログラムや定期的なペネトレーションテストなど) も実施しています。これらのシステムにより、私たちはアクセスの境界に強い自信を持ち、機密データの露出を防ぐための基盤を形成しています。

PermissionsV2の構築方法の詳細についてはこちらをご覧ください。
機密データの露出はセキュリティの脆弱性のひとつで、機密情報や保護された情報が意図せずにアクセス権のない人々に公開され、誤用や信頼の喪失のリスクの原因となります。
しかし、予防策とテストだけでは、すべてのエッジケースを捉えることはできません。Figmaの製品とインフラが複雑になるにつれて、微妙な見落としや予期せぬデータフローのリスクも当然ながら増加しました。よく設計されたシステムであっても、新しい方法でサービスが相互作用する場合や、既存のパスが予想とは異なる動作をする場合には、驚きを生むことがあります。
Figmaにとってデータ保護がどれほど重要であるかをふまえ、検出と観察可能性に焦点を当てた別の防御策を追加したいと考えました。私たちの目標は、予防管理が意図した通りに機能していることを継続的に検証し、生産に影響を及ぼす前に早期に異常を発見できるシステムを構築することでした。
それを可能にするためには、次のことができるシステムが必要でした。
- 露出の可能性がある箇所を、それが製品のどこであっても、継続的に監視する。
- 問題を早期 (理想を言えば、実稼働前) に修正するための実用的なインサイトを提供する。
- 本番環境で防御の強化策としてアクティブに機能し、リアルタイムでリグレッションを検出する。
これらの目標は私たちのアプローチの基盤を形成し、検出範囲、パフォーマンスへの影響、および運用の維持可能性のバランスの取り方を基準となりました。
ステップ1: ファイル識別子のためのResponse Samplingの構築
プログラムで機密データの露出を検出する前に、何が機密と見なされるかを決定する必要がありました。API応答のすべてのフィールドがリスクを引き起こすわけではないので、すでに明確な機密性とアクセスルールが確立されている、十分に定義されたタイプ (つまり、ファイル識別子) から始めました。Figmaのファイル識別子は、各ファイルのURLに埋め込まれ、そのファイルを特定のアクセス制御にリンクする一意のトークンです。ファイル識別子は、高エントロピーのケイパビリティトークンであり、既知の文字セットと一定の長さを持つため、テキストストリームで検出するのが容易です。そのため、認証バグの検出を行う場合や、機密データの体系的な定義が提供された後に広範な応答サンプリングをサポートするインフラストラクチャを構築する場合の、実用的な出発点となりました。

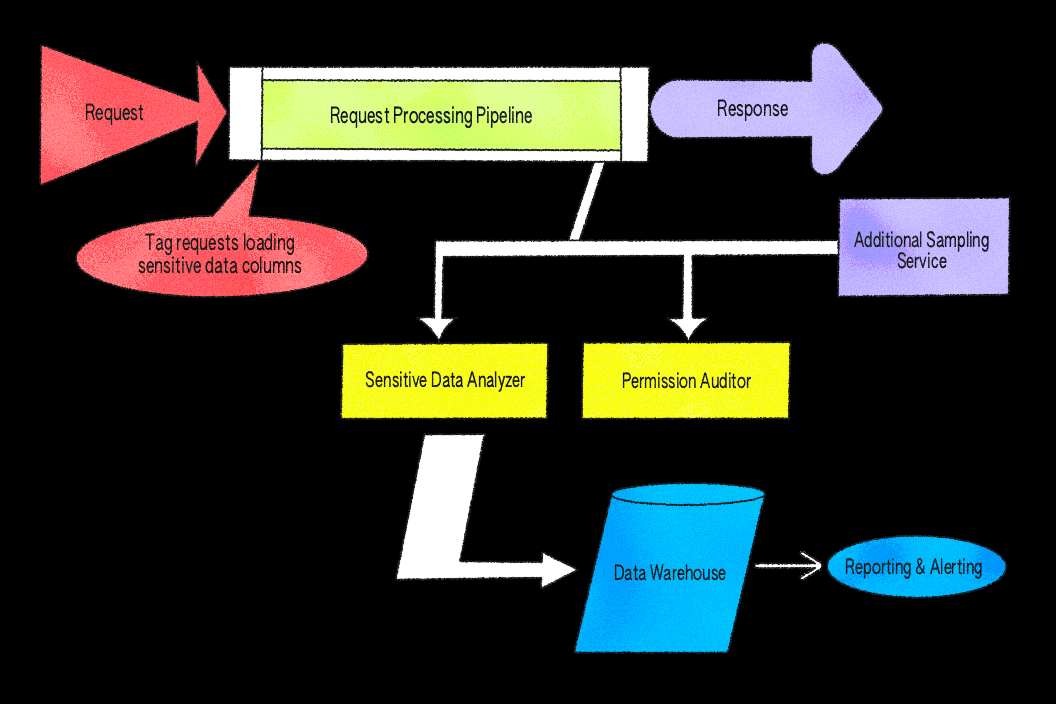
私たちの初期の実装では、このデータ型とそれに関連する権限チェックに焦点を当てていました。アイデアはシンプルでありながら強力でした。主要なサービスからの応答の小さなサブセットをサンプリングし、ファイルに関連付けられた識別子をスキャンし、リクエストしたユーザーが各値にアクセスする権限を持っていることを確認します。サンプリングはリクエストパス全体の設定可能なレートで一様にランダムに行われます。これにより、代表的な結果を表に出しながら、カバレッジを制御し、オーバーヘッドを制限することができます。
私たちはRubyアプリケーションサーバーでミドルウェアとしてシステムを構築しました。これは認証済みユーザーオブジェクト、完全なAPI応答ボディ、および内部権限システムであるPermissionsV2 に直接アクセスできます。これにより、一箇所で応答データを検査し、権限を評価することが簡単になります。Envoyのようなプロキシレイヤーで同様のチェックを実装することもできましたが、その場合、アーキテクチャに必要なユーザーコンテキスト認識の権限評価を実行することが著しく難しくなるでしょう。
Response Samplingの実装には、非同期ジョブとafterブロックを使用しました。afterフィルターは、各リクエストが完了した後に自動的に実行される組み込みフックであり、応答がクライアントに返される前に検査するための一貫した場所となります。このフィルターは、設定されたサンプリング率に従って適格な応答を調査し、JSON本文を解析してファイル識別子を抽出します。関連する識別子が見つかった場合、システムは権限を検証する非同期ジョブをキューに入れます。誤検知を減らすために、検証ロジックは既知の安全なケースを考慮したルールを適用し、予期されない結果のみがレビュー対象となるようにします。これらはすべてノンブロッキングです。サンプリングや検証が失敗しても、リクエストは通常どおり完了し、エラーは監視のためにログに記録されます。
内部エンドポイントにより、他のサービスが独自のサンプリングデータを提出し、処理パイプラインを再利用できるようになります。このサービスには、コラボレーション体験を同期するFigmaのリアルタイムデータ取得サービスであるLiveGraphなどが含まれます。LiveGraphは、応答を生成した後、このエンドポイントに軽量APIコールを行いました。これにより、リアルタイムデータフローに負荷をかけずにResponse Samplingのメリットを受けることができます。パフォーマンスを予測通りに保つため、LiveGraphでのサンプリングは設定とレート制限によって管理されています。所見は他のサービスと同じスキーマとロギングパスを共有しているため、結果はアナリティクスウェアハウスとトリアージダッシュボードで統合され、オンコールエンジニアがその出所に関係なくアラートを解釈することが容易になっています。

LiveGraphの構築方法の詳細についてはこちらをご覧ください。
このロジックを直接APIインフラストラクチャに埋め込み、ステージングと実稼働の両方のトラフィックで実行できるようにしました。サンプリングレートは、意味のある結果を得るために十分なカバレッジを確保しつつ、顕著なレイテンシーが生じないように調整されました。また、すべてのチェックは非同期で実行され、リクエストと応答のサイクルを遅くしないようにしました。さらに、処理パイプラインが過負荷にならないようにするため、また過度なリソースの消費を防ぐために、レート制限が導入されました。
このアプローチにより、貴重なインサイトがすぐに得られるようになりました。導入から数日以内に、Response Samplingで、特定の応答で不要にファイル関連の識別子が返され、データのフィルターの改善が促されるケースがわずかながら明らかになりました。また、一部のファイルがアクセス許可チェックを完全にバイパスする経路を明らかにし、その抜け道を閉じて全体的なアクセス制御を強化することができました。
ステップ1ではコンセプトが証明されましたが、その範囲は限られていました。ファイル識別子は重要ですが、私たちが保護する必要のある機密情報のカテゴリの1つを表しているにすぎません。
ステップ2: 拡張されたResponse Samplingによる表示の向上
Figmaでは、基盤が整ったところで、システムの範囲を広げることにしました。初期の実装は、Response Samplingがリアルな認証の問題を効率よく検出できることを証明しましたが、それは1件のデータ型に限定されていました。次の課題は、あらゆる機密データのフィールドに同じアプローチをスケーリングすることでした。つまり、当社の製品における「機密情報」の意味をシステムに認識させることです。
Expanded Response Samplingは、社内では「ファンシーなResponse Sampling」と呼ばれ、FigTag (社内データ分類ツール) と統合することにより、同じサンプリングの原則をすべての機密データに拡張しました。

FigTagは、その感度と意図された使用状況を説明するカテゴリで、すべてのデータベースの列にアノテーションを付けることで機能します。これらのアノテーションは中央スキーマに保存され、データウェアハウスに伝播されるため、クエリ時に列の感度を簡単に判断できます。これらのカテゴリの1つであるbanned_from_clientsは、感度のシグナルとして機能します。通常の状況下ではAPI応答で返してはいけないフィールド (例えば、セキュリティ関連の識別子、請求の詳細、その他の個人情報) をフラグ付けします。
FigTagと統合することにより、すべてのアプリケーションサーバーのAPIエンドポイントにおいて、任意の機密フィールドを含む応答のサブセットをサンプリングできるようになります。banned_from_clientsとしてタグ付けされた列を含むデータベースレコードがアプリケーションに読み込まれると (ここではActiveRecordモデルを使用しています。これはRubyアプリケーションで使用されるオブジェクトリレーショナルマッピング層です)、コールバックがその値をリクエストローカルストレージに記録します。サンプリングされたリクエストでは、リクエスト中に実際にアクセスされた値のみを追跡することで、不要な負荷を避けます。
レスポンスが生成されると、after フィルターがシリアル化されたJSONを検査し、記録された機密データ値と比較します。レスポンスに機密データ値が含まれている場合は、発見がログに記録されます。以前と同様に、結果は統合されたアナリティクスウェアハウスとダッシュボードにフローします。
また、柔軟な許可リストプロセスを導入しました。これにより、予期しないデータの検出を可能にしたまま、意図的で安全な露出を持つエンドポイントを応答サンプリングから除外できるようなります。例えば、OAuthクライアントシークレットは、認証されたユーザー専用の認証情報管理エンドポイントから意図的に返される場合がありますが、無関係なAPI応答に含まれていると深刻な問題になります。
早期検知の実施
拡張されたResponse Samplingシステムは、コードレビューや手動のQAだけでは見つけることが非常に困難だった小さな問題を明らかにする強力な検出レイヤーとなりました。それにより、ステージングでのリスクを事前に発見し、実稼働環境でのリグレッションに迅速に対応できるようになりました。以下にいくつか例を挙げます。
- 長い間未使用だったデータフィールドが予期しない形でいくつかの応答に入り込んでいることがわかりました。チームはその発見内容を確認し、分類し、ターゲットを絞った修正を迅速にリリースしました。
- システムは、関連するリソースからのデータが明確に必要でないのに応答に含まれていたケースを浮き彫りにし、ターゲットを絞ったクリーンアップ作業を行いました。
- Response Samplingは、アイテムごとにアクセスを個別に検証せずにリソースリストを応答で返しているシナリオを強調し、権限チェックの強化を促しました。
精度とパフォーマンスのバランスについて学んだ教訓
このようなシステムの構築には、Figmaにおけるチーム間の協力が必要です。私たちのセキュリティエンジニアは、プロダクトチームやプラットフォームチームと協力してコードをリリースし、ユーザー向けの機能と同じ創造性と厳密さをもって検出システムに取り組んでいます。
何か月もの間、Response Samplingの構築と運用を進めてきた結果、私たちはプログラムによる検出システムを構築するのに何が必要かについて多くを学びました。
- 常にパフォーマンスへの影響を考慮する: ほんの少しのモニタリングでも、注意深く設計しないとレイテンシーを引き起こすことがわかりました。サンプリングレートを調整し、非同期にチェックを実行することで、ユーザーに対してのパフォーマンスを維持しつつ、トラフィックの状況把握を有意義なものにします。
- 誤検知を管理する (誤検知に振り回されないように!):誤検知率が高いとチームが混乱し、アラートへの信頼が低下する可能性があります。これに対処するために、動的な許可リスト作成と厳密なトリアージワークフローを実装しました。これにより、既知の安全なケースを迅速にフィルターし、エンジニアが本当にリスクのある検出事項に集中できるようになりました。
- コンテキストが重要: すべての機密データの露出が同じように問題を引き起こすわけではありません。動的な構成を使用することで、サービスを再デプロイしなくても検出ルールをすぐに調整できました。これにより、正当な使用事例を慎重に扱いながらも、異常または予期しないシナリオにフラグを立てることができました。
- 層状防御を構築する: システムをステージングおよび本番環境の両方で運用することで、リリース前の早期検出、およびリグレッションを捕捉するための継続的なモニタリングという2つの防御ラインが可能になりました。この多層防御アプローチは、長期的な耐性を維持するために非常に重要でした。

今後の道のり
Response Samplingを活用することで、プラットフォームセキュリティのアプローチを製品のセキュリティに適用しました。継続的なモニタリングと検出をアプリケーションサーフェスに重ねたことにより、開発を遅らせることなく問題を早期に特定できました。
このフレームワークを拡張して、主要なインタラクションチャネル全体で潜在的な露出を特定できるように、より多くのサービスや他のユーザー向け接点をカバーする予定です。また、進化するコンプライアンスのニーズに対応して、さらなるPIIや規制されたデータのクラスなどの、追加の機密データカテゴリにまで対象範囲を拡大する予定です。
システムが拡大してもResponse Samplingの効果性を維持するため、より適応的かつ洞察力のあるものにする方法を模索しています。例えば、リソース消費と表示のバランスを取るための、より細かな単位でのサンプリングコントロールの調査、自動トリアージによる調査の迅速化、経時的なトレンドを明らかにするための、より充実したレポート作成を検討しています。このフレームワークを拡張する中でも、ユーザーデータの保護とFigmaの体験が常に迅速、信頼性、そして安全であることを確保するという目標は変わりません。
AppSecチームがインフラストラクチャセキュリティのアプローチを利用することはあまりありませんが、Response Samplingを構築することで、そのようなアプローチをアプリケーションレイヤーに適用することが効果的になり得ることが分かりました。継続的な検出をアプリケーションレイヤーにより近づけることで、問題をより早く見つけ、迅速に対応できるようになりました。他のチームでも導入によるメリットがあると思います。

エンジニア募集中! Figmaでの働き方について詳しくは、募集中のポストをご覧ください。





