



멀티데이 지연에서 거의 실시간 인사이트로: Figma의 데이터 파이프라인 업그레이드




사용자와 데이터의 기하급수적인 증가 이후, 일상적인 동기화 작업은 완료하는 데 몇 시간 또는 며칠이 걸리기 시작했습니다. 데이터 파이프라인을 재구축하여 지연을 거의 실시간에 가깝게 줄이는 방법입니다.
멀티데이 지연에서 거의 실시간 인사이트로: Figma의 데이터 파이프라인 업그레이드공유
일러스트: Cynthia Alfonso
Figma는 2021년 FigJam 출시, 2023년 Dev Mode 출시, 2025년 Figma Make 출시, 그리고 한국, 브라질, 일본, 스페인 시장을 위한 전체 현지화를 포함하여 지난 5년 동안 빠르게 성장했지만, 이러한 성장에는 도전 과제가 따랐습니다. 사용자 기반이 확장됨에 따라 플랫폼에서 매일 생성되는 데이터의 양과 복잡성도 함께 증가했습니다.
작년에 우리는 데이터베이스 팀이 온라인 관계형 데이터베이스를 어떻게 수평 확장했는지에 대한 비하인드 스토리를 공유했습니다. 하지만 온라인 데이터베이스에서 분석 웨어하우스로 데이터를 전송하는 우리의 레거시 동기화 시스템은 속도를 따라잡는 데 어려움을 겪었습니다. 분석 웨어하우스는 회사의 주요 핵심 성과 지표(KPI)를 포함한 중요한 비즈니스 인사이트를 제공하는 곳입니다.

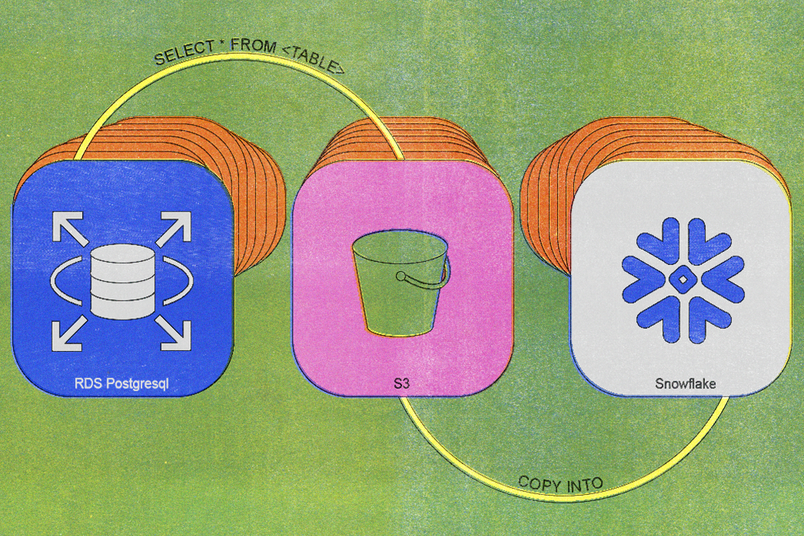
2020년에 첫 번째 레거시 동기화 프로세스를 구축했는데, 아키텍처는 단순했습니다. 매일 크론 작업이 단순한 SELECT * FROM <TABLE> 쿼리를 실행하고, 결과 데이터를 S3에 업로드한 다음, 그 데이터를 Snowflake로 가져오는 방식이었습니다.
처음에는 이 방법이 잘 작동했습니다. 그러나 테이블이 커지고 삽입 작업이 집중적으로 발생함에 따라 시스템의 한계가 드러나기 시작했습니다. 2023년에는 일일 동기화 작업을 완료하는 데 약 6시간이 걸렸고, 일일 내보내기 작업을 지원하기 위해 별도의 데이터베이스 복제본을 유지해야 했습니다. 가장 큰 테이블의 경우 동기화 시간이 며칠 이상 걸리기도 했습니다.
결국 합리적인 시간 내에 데이터를 동기화하기가 거의 불가능해졌고, 데이터를 분석하고 정보에 입각한 결정을 내리는 능력이 심각하게 저해되었습니다.
우리는 세 가지 솔루션을 검토했습니다.
- 기존 레거시 동기화 프로세스 유지: 동기화 지연 문제와 추가 데이터베이스 복제본 유지로 인해 매년 수백만 달러의 불필요한 비용이 발생했기 때문에, 이 방안은 오래지 않아 유지하기 어렵게 되었습니다.
- 빠른 해결책으로 병렬 처리 추가: 동기화 프로세스가 작업을 동시에 수행할 수 있도록 병렬 처리를 추가하는 방안을 고려했으나, 이는 확장성이 없는 것으로 판명되었습니다.
- 데이터 동기화 프로세스의 전면적 개편: 이는 더 오랜 기간에 걸쳐 더 큰 투자가 필요하지만, 가장 확장성이 우수한 접근 방식이며, Figma가 계속 성장함에 따라 지속 가능할 가능성이 가장 높았습니다.
증분 동기화는 전체 데이터세트를 반복적으로 전송하는 대신 소스 데이터베이스의 최근 변경 사항만 캡처하여 적용함으로써 분석 데이터베이스를 효율적으로 최신 상태로 유지하도록 설계된 데이터 파이프라인 기술입니다. 이는 데이터 전송 시간과 리소스 사용량을 크게 줄여줍니다.
옵션들을 살펴본 결과 우리의 선택은 명백했습니다. 우리는 장기적인 관점으로 초점을 옮겨 지속 가능하고 효율적인 결과를 약속하는 솔루션인 증분 동기화 작업에 착수했습니다.
구매 또는 자체 구축
증분 동기화가 작동하려면 데이터베이스 테이블 스냅샷, 변경 데이터 캡처(CDC) 스트림, 증분 병합 지원이 필요합니다. 증분 동기화의 잠재력을 살펴볼수록 우리는 이를 직접 구축해야 한다는 것을 알게 되었습니다. 우리는 독점적인 엔드투엔드 솔루션 구매를 고려했지만, 유연성, 비용, 확장성 측면에서 우리의 요구를 충족하는 옵션은 없었습니다.
유연성: 우리가 찾은 많은 범용 SQL 호환 도구들은 벤더별 특정 기능을 효과적으로 활용하지 못했습니다. 예를 들어, PostgreSQL용 Amazon RDS의 API를 사용하면 별도의 데이터베이스 복제본을 유지하는 오버헤드 없이 직접 스냅샷을 생성할 수 있었지만, 범용 옵션들은 이를 활용하지 않았습니다. 벤더 솔루션을 선택한다면 기존 보유 기술을 기반으로 업무 흐름을 최적화할 수 있는 유연성을 갖지 못할 것이었습니다.
비용: 또한 많은 옵션이 우리 규모에서는 상당한 추가 비용을 요구했습니다. 비용을 산정해 본 결과, 독점 솔루션은 자체 구축 솔루션보다 5~10배 더 많은 비용이 들 것으로 예상되었습니다.
확장성: 도구의 확장성이 뛰어났다면 비용을 지불할 가치가 있었겠지만, 많은 도구가 우리의 현재 및 증가하는 요구 사항을 충족할 만큼 충분히 확장성이 우수하지 않다는 점을 발견했습니다. 우리는 2020년에 레거시 동기화 프로세스를 구축했고, Figma는 여전히 성장하고 있습니다. 자체 구축을 통해 우리는 미래의 요구 사항에 대응하여 빠르게 혁신할 수 있음을 보장합니다.
하위 수준 컴포넌트 구축 및 결합
맞춤형 파이프라인을 구축함으로써 우리는 정확한 인프라 요구 사항(및 팀의 전문성)에 부합하는 하위 수준 컴포넌트(오픈 소스 또는 관리형 서비스)를 찾아 결합할 수 있었습니다.
스냅샷에는 초기 테이블 복사본을 S3로 내보낼 수 있는 Amazon RDS를 사용합니다. CDC에는 Kafka Connect를 사용합니다. 이는 Snowflake 커넥터와 통합되어 Amazon MSK(Managed Streaming for Apache Kafka)에서 호스팅될 때 효율적인 스트리밍을 제공합니다. 증분 병합을 위해 우리는 Snowflake 저장 프로시저를 통해 사용자 지정 병합 로직을 구현하고 Snowflake 작업을 통해 프로세스를 자동화했습니다.
새로운 파이프라인 아키텍처 구축
모든 새로운 프로젝트에서 우리는 작업을 안내하고 목표와 결정을 형성하는 설계 원칙을 개요로 작성합니다. 이 프로젝트를 위해 다음과 같은 네 가지 원칙을 정의했습니다.
- 지연 시간: 데이터의 엔드투엔드 동기화 시간을 단축합니다.
- 비용: 비용을 절감하고 지속적인 성장 속에서도 낮은 비용을 유지합니다.
- 규정 준수: 관련된 모든 데이터 규제 표준을 준수합니다.
- 데이터 무결성: 수명 주기 전반에 걸쳐 데이터가 정확하고, 완전하며, 일관되고, 신뢰할 수 있도록 보장하는 업무 흐름을 사용합니다.

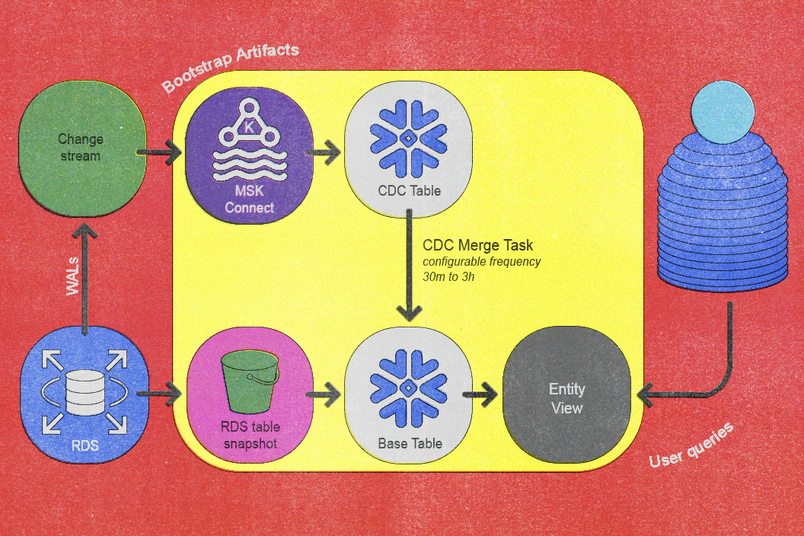
궁극적으로 이러한 원칙들은 '부트스트랩 업무 흐름'과 '검증 업무 흐름'이라는 두 가지 기본 업무 흐름을 통해 증분 동기화를 달성하는 재구상된 데이터 파이프라인으로 구현되었습니다. 부트스트랩 업무 흐름은 새로운 테이블을 파이프라인에 통합하고, 검증 업무 흐름은 데이터가 파이프라인으로 유입될 때 데이터의 정확성을 검증합니다. 이 두 업무 흐름이 함께 작동하여 데이터가 효율적으로 흐르고 가능한 한 일관되고 정확하게 유지되도록 보장합니다.
부트스트랩 업무 흐름
동기화 파이프라인에 새로운 테이블을 통합하기 위한 온보딩 프로세스는 다음과 같은 자동화되고 명확하게 정의된 단계로 구성되어 있습니다.
- 기존 CDC 서비스가 Postgres에서 새 테이블을 캡처하고 Kafka의 테이블별 토픽에 이벤트를 게시합니다. 우리는 기존 사내 CDC 서비스를 사용하여 이 단계를 자동화하고 데이터베이스 시스템의 토폴로지와 통합했습니다.
- Amazon RDS의 스냅샷 내보내기 프로세스를 사용하여 최신 일일 데이터베이스 스냅샷을 S3로 전송합니다(테이블 크기에 따라 시간이 오래 걸릴 수 있음).
- 스냅샷이 S3로 성공적으로 내보내지면,
Snowflake의 COPY INTO <table>쿼리가 S3에서 데이터를 가져와 Snowflake의 전용 엔터티별 기본 테이블로 가져옵니다. - MSK Connect 내의 Snowflake Sink Connector는 Kafka 주제 내용을 Snowflake의 각 엔터티 CDC 테이블에 스트리밍하여 Kafka 시작 오프셋이 스냅샷 타임스탬프보다 이전임을 보장합니다.
- 우리가 개발한 사용자 지정
MERGE저장 프로시저를 주기적으로 실행하도록 Snowflake 작업을 예약합니다. - 동기화가 최근 변경 사항을 충분히 따라잡으면, 사용자가 쉽게 쿼리할 수 있도록 기본 테이블 위에 가벼운 보기를 생성하여 온보딩을 완료합니다.
우리는 스키마 진화와 같은 이벤트를 관리하는 데 중요한 무중단 리부트스트랩기능을 구현했습니다. 이를 위해 최종 사용자용 보기를 제외한 모든 부트스트랩 아티팩트의 버전을 관리하여, 라이브 운영을 중단하지 않고 병렬 부트스트랩을 수행할 수 있게 지원했습니다. 새 버전으로의 승격은 원자적 보기 업데이트 단계를 통해 매끄럽게 이루어집니다.
유효성 검사 업무 흐름
디자인이 견고함에도 불구하고, 데이터 파이프라인은 부분적 실패, 잘못 구성된 컴포넌트, 소프트웨어 버그 또는 예상치 못한 소스 데이터 이상으로 인한 데이터 손상 위험이 필연적으로 존재합니다. 스냅샷 내보내기, CDC 이벤트 캡처, 증분 병합 등 다양한 지점에서 문제가 발생할 수 있으며, 이를 방치할 경우 모르는 상태에서 데이터가 불일치하거나 분석 결과가 잘못되는 결과를 초래할 수 있습니다.
따라서 아키텍처의 또 다른 중요한 측면은 데이터 정확성 검증을 전담하는 강력한 검증 업무 흐름이며, 다음과 같이 작동합니다.
- 라이브 기본 테이블을 복제하여 소스로 지정합니다.
- 기본 및 CDC 테이블을 타겟(target)이라는 임시 스키마로 내보내도록 명시적으로 구성된 부트스트랩 업무 흐름을 실행합니다. 이는 자동 병합을 시작하지 않고 실행됩니다.
- 일관성을 보장하기 위해 내보낸 CDC 데이터를 사용하여 소스 및 타겟 기본 테이블을 동일한 시점 위치로 정렬합니다.
- 소스 테이블과 타겟 테이블 간에 정밀한 셀 단위 비교를 수행합니다.
- 이러한 비교에서 상세한 결과를 생성하고 이를 모니터링 및 알림 시스템에 통합합니다.
이러한 엄격한 셀 수준의 CDC 인식 검증은 데이터 무결성에 대한 절대적인 확신을 제공하며, 서비스 출시 전후의 신뢰성을 크게 높여 줍니다.
자동화에 투자하기
자동화가 없었다면 이곳에서의 성공도 없었을 것입니다. 우리가 구축한 파이프라인은 수많은 네트워크 호출과 종속성에 걸친 광범위한 오케스트레이션이 필요했고, 이 모든 것을 하나로 묶기 위해 임시 및 예약된 자동화가 모두 필요했습니다.
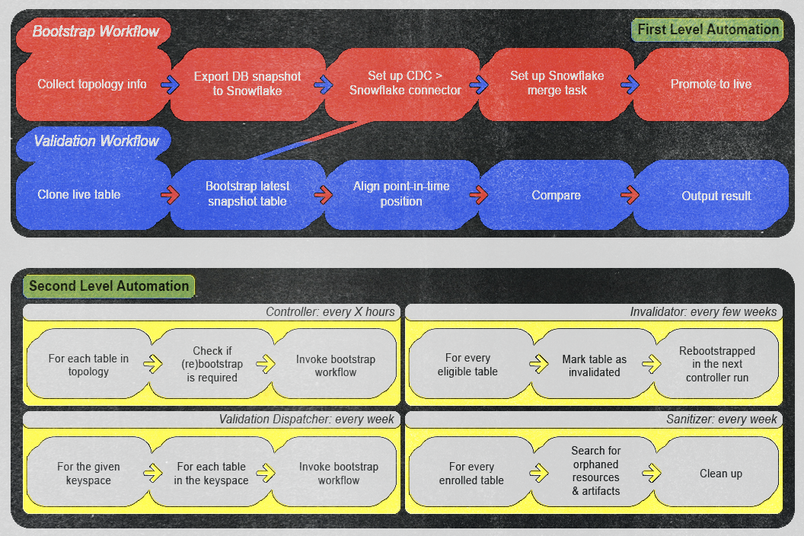
AWS Step Functions를 사용하여 자동화를 두 가지 범주로 정리했습니다.
1단계 자동화: 수동으로 또는 임시로 트리거할 수 있는 업무 흐름이 포함됩니다. 엔터티 이름만 제공하면 부트스트랩 또는 검증 프로세스를 실행하도록 설계했습니다. 일단 실행되면 모니터링에서 경고가 발생하지 않는 한 수동 개입이 필요하지 않습니다. 파이프라인의 실제 버그이든 검증 로직의 오탐이든, 운영자가 즉각 조치를 취할 수 있도록 알림을 확실하게 하고, 재발 방지 및 높은 운영 효율성과 신뢰성을 유지하기 위한 명확한 조치 항목을 제공하도록 했습니다.
2단계 자동화: 특정 조건과 일정에 따라 1단계 자동화를 호출하도록 설계된 업무 흐름이 포함됩니다. 1단계가 무거운 작업을 수행하고, 2단계는 현재 상태를 자동으로 확인하여 1단계 자동화를 트리거해야 하는지 판단합니다. 예시는 다음과 같습니다.
- 컨트롤러 업무 흐름은 온보딩 또는 리부트스트래핑할 수 있는 새로운 엔터티를 몇 시간마다 정기적으로 확인합니다.
- 검증 디스패처 업무 흐름은 매주 각 테이블에 대한 검증 업무 흐름을 자동으로 시작합니다.
- 무효화 업무 흐름은 데이터 무결성을 보장하기 위해 각 테이블에 대해 매주 리부트스트랩 작업을 수행합니다.
- 정리 업무 흐름은 매주 잠재적인 고아 아티팩트를 정기적으로 정리하여 깔끔하고 효율적인 환경을 유지합니다.

우리는 테스트 시 공격적인 접근 방식을 취했습니다. 스테이징 환경의 엄격한 자동화 루틴이 매주 모든 테이블을 자동으로 리부트스트랩하여 잠재적인 문제를 시뮬레이션하고 사전에 발견합니다. 이러한 방식을 통해 테스트 시작 일주일 만에 심각한 실패 모드를 식별하면서 성과를 거두었습니다. 이 문제는 프로덕션에 도달했다면 최소 20분 동안 사이트가 전면적으로 중단되었을 겁니다. 이를 조기에 발견함으로써 실제 프로덕션 배포 시 안정성을 확보했습니다.
이런 사례들은 완전 자동화가 우리의 지향점이어야 한다는 믿음을 뒷받침했습니다. 일부 업무 흐름을 완전 자동화하는 것이 어렵거나 위험해 보일 때도, 우리는 중간 단계로 부분 자동화를 구현하면서 점진적으로 완전 자동화를 향해 나아갔습니다. 이러한 접근 방식 덕분에 시스템 신뢰성을 꾸준히 개선하고 시간이 지남에 따라 운영 오버헤드를 줄일 수 있었습니다.
운영은 매끄럽게 유지되었으며, 출시 중이나 그 이후에 주요 사고는 한 건도 발생하지 않았습니다.
더 나은 실시간 인사이트를 위한 새로운 기능
새로운 아키텍처로 전환하면서 향상된 유연성과 자동화 기능은 새로운 기능을 개발할 기회가 열렸습니다. 세 가지 주요 개선 사항이 사용자 경험과 개발자 생산성을 크게 향상시켰습니다.
구성 가능한 데이터의 최신성
최종 사용자 피드백을 바탕으로, 우리는 모든 엔터티의 기본 최신성과 Snowflake 컴퓨팅 비용 간의 균형을 맞추기 위해 기본 병합 빈도를 3시간 간격으로 설정했습니다. 또한 더 빈번한 업데이트가 필요한 테이블을 위해 구성 가능한 오버라이드 기능을 도입했습니다. 예를 들어, 청구 파이프라인은 30분 단위 재정의 설정으로 큰 혜택을 보았으며, 이를 통해 전체적인 엔드투엔드 파이프라인 지연 시간을 상당히 줄였습니다.
요청 시 동기화
병합 작업 대기열 시스템 덕분에 우리는 언제든지 안전하게 병합을 트리거할 수 있습니다. 이러한 안전성을 바탕으로 정기적인 자동 일정 외에도 수동으로 즉시 데이터 동기화를 지원하는 사용자 친화적인 CLI 도구를 도입할 수 있었습니다. 이를 통해 필요할 때마다 Snowflake에서 최신 온라인 데이터베이스 데이터에 적시에 액세스할 수 있습니다.
Snowflake에서의 CDC 데이터 검사
CDC 데이터는 이미 내부 목적으로 Snowflake로 가져오고 있었기 때문에, 우리는 엔터티의 현재 상태뿐만 아니라 그 상태에 이르게 된 변경 순서를 탐색하여 더 깊은 인사이트를 얻고자 하는 최종 사용자들에게 이 데이터를 공개했습니다. 사고 대응 시, 이 기능은 예상치 못한 데이터베이스 쓰기 활동을 디버깅할 수 있는 안전한 오프라인 환경을 제공합니다. 예를 들어, 개발자는 "지난주 특정 팀 내 사용자에 대한 모든 이메일 삽입/업데이트/삭제 이벤트 검색"과 같은 쿼리를 수행할 수 있습니다. 또한 온디맨드 동기화 기능을 함께 사용하면 개발자는 Snowflake에서 이 데이터를 거의 실시간으로 쿼리할 수 있습니다. 데이터 보존 정책을 준수하고 무기한 스토리지 증가를 방지하기 위해 CDC 데이터는 사전에 정의된 기간이 지나면 자동으로 삭제됩니다.
결과
이 프로젝트는 시간, 노력, 자원의 상당한 투자가 필요했지만, 기대 이상의 결과를 내며 그 보상을 받았습니다.
데이터 최신성 향상
데이터 최신성을 획기적으로 개선했습니다. 이전에는 데이터가 종종 30시간 이상 지난 상태였습니다. 이제 데이터는 3시간 이내의 최신 상태를 유지하며, 사용자는 분 단위까지 최신성을 설정할 수 있는 유연성을 누릴 수 있게 되었습니다.
확장성 탁월한 성능
이 파이프라인은 이제 이전보다 10배 이상 큰 테이블을 안정적으로 처리하며, Figma가 계속 성장함에 따라 일관되고 예측 가능한 성능을 제공합니다.
개발자 생산성
새로운 도구는 항상 업무 흐름 중단 가능성을 내포하고 있으므로, 우리는 팀 인터뷰를 통해 니즈를 파악하고 팀이 잘 알고 있는 시스템과 파이프라인을 통합함으로써 신뢰를 구축했습니다.
작업이 완료된 후, 운영 오버헤드를 줄이고 분석 웨어하우스 내 온라인 데이터에 거의 실시간으로 액세스할 수 있게 됨으로써 개발자 생산성이 크게 향상되었음을 보여줄 수 있었습니다.
개발자는 이제 몇 분 내의 최신 상태와 변경 이력을 모두 안전하게 쿼리할 수 있어, 더 빠른 사고 대응, 더 안전한 롤아웃, 더 깊은 인사이트를 얻을 수 있습니다.
비용 효율성
구현 초기 단계에서 우리는 수평으로 샤딩된 데이터베이스 지원을 우선순위로 두었습니다. 수평으로 샤딩된 데이터베이스는 테이블 수는 적지만 각각 자체 배치 복제본을 가진 더 많은 데이터베이스 머신을 사용하므로, 이러한 지원은 높은 투자 수익률(ROI)을 보였습니다. 이제 이 파이프라인은 인프라 및 리소스 활용을 지능적으로 최적화하고, 중복 처리를 제거하며, 비즈니스 성장에 따라 원활하게 확장함으로써 연간 수백만 달러의 비용 절감 효과를 제공합니다.
미래의 기회들
우리의 새로운 아키텍처는 데이터 파이프라인을 더욱 개선하고 확장할 수 있는 몇 가지 흥미로운 기회의 토대를 마련했습니다.
- 완전 자동화된 온보딩: 현재 온보딩은 허용 목록에 테이블을 추가하기 위해 전체 요청이 필요하며, 이는 온보딩 프로세스에 마찰을 일으킵니다. 데이터베이스 토폴로지를 파이프라인에 직접 통합하면 테이블 온보딩을 완전히 자동화하여 개발자 경험을 간소화하고 수동 오버헤드를 줄일 수 있습니다.
- 특정 시점 테이블 지원: CDC 데이터를 사용하여 정의된 CDC 보존 기간 내의 어느 시점에서든 테이블 상태를 쿼리할 수 있는 기능을 제공할 수 있습니다. 이 기능을 구현하면 디버깅 기능, 사고 대응, 분석적 유연성이 크게 개선될 것입니다.
- 점진적으로 새로 고쳐지는 다운스트림 모델: 많은 다운스트림 분석 모델이 여전히 기존의 배치 프로세스를 사용하여 구축되고 있습니다. 새로운 파이프라인을 통해 이러한 모델을 점진적으로 새로 고칠 수 있게 되면, 전체 분석 업무 흐름의 효율성을 획기적으로 개선하고 지연 시간을 줄일 수 있습니다.
이 야심찬 변혁은 Figma의 데이터 인프라 팀의 현재 및 이전 구성원인 Amadeo Casas, Alex Tian, Brandon Choi, Carter Bian, David Mah, Dorothy Chen, Ebuka Akubilo, Jimmy Xie, Krish Chainani, Merry Song, Michael Wu, Peng Wang, Raunak Agnihotri, Santosh Muthukrishnan, Xinxin Dai, Zubair Saiyed 님의 경이로운 헌신과 노력으로 실현할 수 있었습니다.
또한 지원을 아끼지 않은 파트너 팀에게도 특별한 감사와 인정을 전합니다. Asheesh Laroia, Dylan Visher, Gordon Yoon, Gustavo Angulo Mezerhane, Langston Dziko, Ping-Min Lin, Sammy Steele, Sean Rice, Yazad Khambata 님, 감사합니다.

현재 엔지니어를 채용 중입니다! Figma에서의 생활에 대해 더 알아보고채용 중인 직무를 확인해 보세요.