



De latência de vários dias a insights quase em tempo real: a atualização do pipeline de dados do Figma




Após um crescimento exponencial de usuários e dados, as tarefas diárias de sincronização começaram a levar horas ou até dias para serem concluídas. Veja como a reconstrução de um pipeline de dados reduziu a latência para quase tempo real.
Compartilhar De latência de vários dias a insights quase em tempo real: a atualização do pipeline de dados do Figma
Ilustrações por Cynthia Alfonso
O Figma cresceu rapidamente nos últimos cinco anos, incluindo o lançamento do FigJam em 2021, Dev Mode em 2023, Figma Make em 2025, e a completa localização para atender aos mercados brasileiro, japonês, espanhol e coreano — mas esse crescimento traz desafios. À medida que nossa base de usuários aumentou, o mesmo aconteceu com o volume e a complexidade dos dados que nossa plataforma gera todos os dias.
No ano passado, compartilhamos a história interna de como nossa equipe de Bancos de Dados escalou horizontalmente nossos bancos de dados relacionais online. Mas nosso sistema de sincronização legado — responsável por transferir dados de nossos bancos de dados online para nosso armazém analítico, que impulsiona insights críticos de negócios, incluindo KPIs principais da empresa — estava tendo dificuldades para acompanhar.

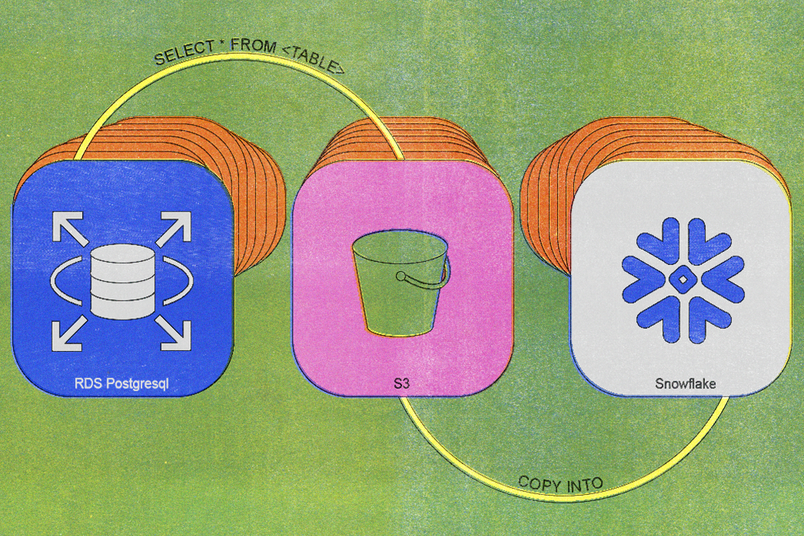
Criamos nosso primeiro processo de sincronização legado em 2020, e a arquitetura era simples: um cron job diário executava uma consulta simples SELECT * FROM <TABLE>, carregava os dados resultantes para o S3 e importava esses dados para o Snowflake.
Inicialmente, isso funcionou bem. No entanto, à medida que as tabelas ficaram maiores e mais sujeitas a inserções, as limitações do sistema ficaram evidentes. Em 2023, as tarefas diárias de sincronização estavam levando cerca de seis horas para completar, e tivemos que manter réplicas adicionais do banco de dados para suportar as exportações diárias. Nossas maiores tabelas apresentavam tempos de sincronização de vários dias ou mais.
Finalmente, tornou-se quase impossível sincronizar nossos dados dentro de um prazo razoável, prejudicando severamente nossa capacidade de analisar dados e tomar decisões informadas.
Avaliamos três soluções:
- Manter nosso processo de sincronização legado: Isso rapidamente se tornou insustentável, tanto devido aos atrasos na sincronização quanto porque manter réplicas extras do banco de dados resultou em milhões de dólares em custos desnecessários a cada ano.
- Adicionando paralelismo como uma solução rápida: Consideramos adicionar paralelismo, o que permitiria que o processo de sincronização realizasse operações simultâneas, mas isso se mostrou insustentável.
- Revisar completamente o processo de sincronização de dados: Isso exigiria um investimento maior durante um período mais longo, mas seria a abordagem mais escalável e a mais provável de durar à medida que o Figma continua a crescer.
Sincronização incremental é uma técnica de pipeline de dados projetada para manter eficientemente os bancos de dados analíticos atualizados, capturando e aplicando apenas as mudanças recentes do banco de dados de origem, em vez de transferir repetidamente conjuntos de dados inteiros. Isso reduz significativamente o tempo de transferência de dados e o uso de recursos.
Observando as opções, nossa escolha ficou clara: Mudamos nosso foco para o longo prazo e começamos a trabalhar na sincronização incremental – uma solução que prometia resultados sustentáveis e eficientes.
Comprar vs. construir
Para funcionar, a sincronização incremental requer suporte a instantâneos de tabelas de banco de dados, streams de captura de dados de alteração (CDC) e mesclagem incremental. Quanto mais analisávamos o potencial da sincronização incremental, mais percebíamos que teríamos que construí-la nós mesmos. Consideramos comprar uma solução proprietária de ponta a ponta, mas nenhuma opção atendia nossas necessidades em termos de flexibilidade, custo e escala.
Flexibilidade: Muitas ferramentas genéricas compatíveis com SQL que encontramos não usaram efetivamente as capacidades específicas dos fornecedores. As APIs do Amazon Relational Database Service (RDS) para PostgreSQL, por exemplo, nos permitiriam gerar instantâneos diretamente sem a sobrecarga de manter uma réplica de banco de dados separada, mas as opções genéricas não aproveitaram isso. Se escolhêssemos uma solução de fornecedor, não teríamos a flexibilidade para otimizar nosso fluxo de trabalho com base na tecnologia existente que temos.
Custo: Muitas opções também teriam um custo adicional significativo na nossa escala. Quando precificamos nossas opções, projetamos que soluções proprietárias custariam de cinco a dez vezes mais do que uma solução interna.
Escala: O custo poderia ter valido a pena se essas ferramentas pudessem escalar, mas descobrimos que muitas não eram suficientemente escaláveis para nossas necessidades atuais e crescentes. Nós construímos nosso processo de sincronização legado em 2020, e o Figma continua crescendo. Ao construir internamente, garantimos que podemos inovar rapidamente em resposta às necessidades futuras.
Construindo e combinando componentes de nível inferior
Ao construir um pipeline personalizado, pudemos encontrar e combinar componentes de nível inferior—sejam eles de código aberto ou serviços gerenciados—que estavam alinhados exatamente com nossos requisitos de infraestrutura (e com a expertise de nossa equipe).
Para instantâneos, usamos Amazon RDS, que pode exportar para S3 para cópias iniciais de tabelas. Para CDC, usamos Kafka Connect, que oferece streaming eficiente uma vez integrado com um Conector Snowflake e hospedado no Amazon Managed Streaming for Apache Kafka (MSK). Para a mesclagem incremental, implementamos lógica de mesclagem personalizada por meio de procedimentos armazenados do Snowflake e processos automatizados via tarefas do Snowflake.
Construindo uma nova arquitetura de pipeline
Com cada novo projeto, delineamos princípios de Design que orientam o trabalho, moldando nossos objetivos e decisões. Para este projeto, definimos quatro princípios:
- Latência: Reduzir o tempo para sincronizar dados de ponta a ponta.
- Custo: Reduzir custos e mantê-los baixos mesmo enquanto continuamos a crescer.
- Conformidade: Manter a conformidade com todos os padrões regulatórios de dados relevantes.
- Integridade dos dados: Utilizar fluxos de trabalho que garantam que os dados permaneçam precisos, completos, consistentes e confiáveis ao longo de seu ciclo de vida.

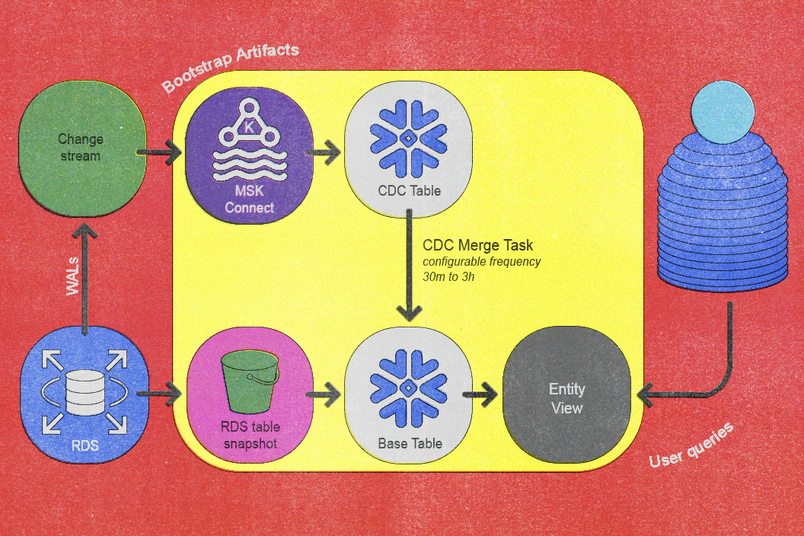
Por fim, esses princípios foram traduzidos em um pipeline de dados reinventado que alcança a sincronização incremental por meio de dois fluxos de trabalho fundamentais: um fluxo de trabalho de inicialização e um fluxo de validação. O fluxo de trabalho de inicialização integra novas tabelas ao pipeline, e o fluxo de validação verifica a correção dos dados à medida que eles fluem para o pipeline. Juntos, esses dois fluxos de trabalho garantem que os dados fluam de forma eficiente e permaneçam o mais consistentes e corretos possível.
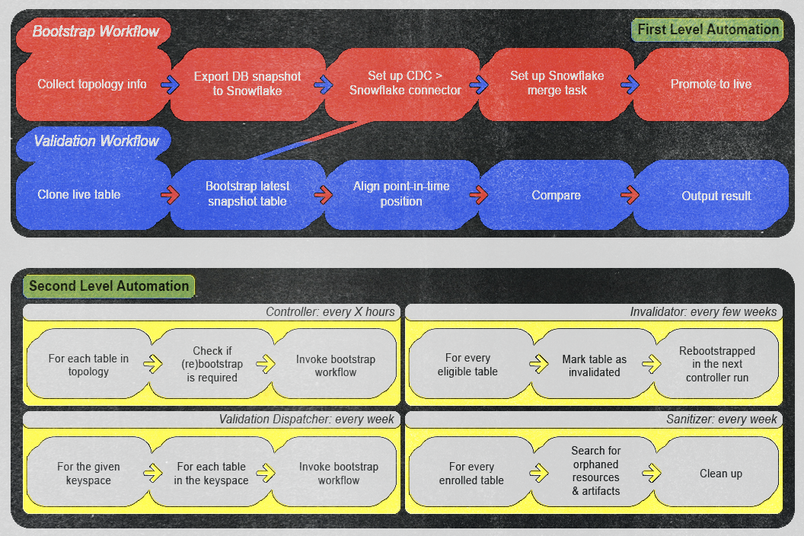
Fluxo de trabalho Bootstrap
Nossa integração de novas tabelas no pipeline de sincronização consiste nos seguintes passos automatizados e claramente definidos:
- O serviço de CDC existente captura a nova tabela do Postgres e publica eventos nos tópicos por tabela do Kafka. Automatizamos essa etapa usando nosso serviço de CDC interno existente e o integramos à topologia do sistema de banco de dados.
- Transferimos o último instantâneo diário do banco de dados para o S3 usando o processo de exportação de instantâneos do Amazon RDS (que pode ser demorado dependendo do tamanho da tabela).
- Uma vez que o instantâneo é exportado com sucesso para o S3, a consulta
COPY INTO <table>do Snowflake importa os dados do S3 para as tabelas base dedicadas a cada entidade no Snowflake. - Um Conector de Sink Snowflake dentro do MSK Connect transmite conteúdos de tópicos Kafka para as tabelas CDC por entidade do Snowflake, garantindo que o offset inicial do Kafka preceda o timestamp do instantâneo.
- Agendamos uma tarefa no Snowflake para executar periodicamente um procedimento armazenado
MESCLARpersonalizado que desenvolvemos. - Quando a sincronização captura suficientemente as mudanças recentes, criamos uma forma leve de visualizar sobre a tabela base para facilitar a consulta do usuário, o que completa a integração.
Implementamos uma capacidade de re-inicialização sem tempo de inatividade, que é crucial para gerenciar eventos como a evolução do esquema. Para fazer isso, versionamos todos os artefatos de bootstrap, exceto a visualização final voltada para o usuário, o que permite a inicialização paralela sem interromper as operações em tempo real. A promoção para a nova versão ocorre de forma perfeita através de uma etapa de atualização atômica da visualização.
Fluxo de trabalho de validação
Apesar de designs robustos, pipelines de dados inevitavelmente correm o risco de corrupção de dados devido a falhas parciais, componentes mal configurados, bugs de software ou anomalias inesperadas nos dados de origem. Problemas podem surgir em vários pontos - desde exportar instantâneos e capturas de eventos CDC até mesclar incrementais - e podem causar inconsistências silenciosas de dados ou resultados analíticos incorretos se não forem verificados.
Portanto, outro aspecto crítico da arquitetura é um fluxo de trabalho de validação robusto dedicado a verificar a correção dos dados, que opera da seguinte forma:
- Clone a tabela base ao vivo, que designamos como a fonte.
- Execute o fluxo de trabalho de bootstrap, que configuramos explicitamente para exportar as tabelas base e CDC para um esquema temporário, rotulado como o destino. Isso é executado sem iniciar a mesclagem automatizada.
- Alinhe as tabelas base de origem e destino em posições idênticas no tempo usando os dados CDC exportados para garantir consistência.
- Realize comparações precisas, célula a célula, entre tabelas de origem e destino.
- Gere saídas detalhadas a partir dessas comparações e integre os resultados em nossos sistemas de monitoramento e alerta.
Essa validação rigorosa, em nível de célula e com conhecimento de CDC, fornece confiança absoluta na integridade dos dados, aumentando substancialmente a confiabilidade antes e depois do lançamento do serviço.
Investindo em automação
O sucesso aqui não seria possível sem automação. O pipeline que construímos exigiu uma orquestração extensa por meio de inúmeras chamadas de rede e dependências, e precisávamos de automação tanto sob demanda quanto programada para integrar tudo.
Usando o AWS Step Functions, organizamos nossa automação em duas categorias:
Automação de primeiro nível: Esta categoria inclui fluxos de trabalho que podemos acionar manualmente e ad hoc. Nós os projetamos para executar processos de bootstrap ou validação fornecendo apenas o nome da entidade. Uma vez executados, esses fluxos de trabalho não requerem intervenção manual, a menos que o monitoramento gere um alerta. Garantimos que os alertas sejam altos o suficiente para motivar ação imediata do operador — seja um bug real no pipeline ou um falso positivo na lógica de validação — e fornecemos itens de ação claros para prevenir recorrências e manter alta eficiência operacional e confiabilidade.
Automação de segundo nível: Esta categoria inclui fluxos de trabalho que projetamos para invocar automações de primeiro nível com base em condições e horários específicos. O primeiro nível faz o trabalho pesado, e o segundo nível verifica automaticamente os estados atuais para ver se precisamos acionar uma automação de primeiro nível. Exemplos incluem:
- Um fluxo de trabalho controlador verifica regularmente a cada poucas horas por novas entidades disponíveis para integração ou re-inicialização.
- Um fluxo de trabalho de despacho de validação inicia automaticamente os fluxos de trabalho de validação para cada tabela semanalmente.
- Um fluxo de trabalho invalidado realiza operações de rebootstrap semanais em cada tabela para garantir a integridade dos dados.
- Um fluxo de trabalho de sanitização rotineiramente limpa artefatos potencialmente órfãos toda semana, mantendo um ambiente limpo e eficiente.

Adotamos uma abordagem agressiva para testes: uma rotina rigorosa de automação em nosso ambiente de preparação que reconfigura automaticamente todas as tabelas toda semana para simular e descobrir proativamente possíveis problemas. Isso valeu a pena quando identificamos um modo de falha grave apenas uma semana após o início dos testes. Esse problema teria resultado em uma interrupção em todo o site que duraria pelo menos vinte minutos, se tivesse chegado à produção. Ao capturar isso cedo, garantimos estabilidade durante implantações reais de produção.
Casos como este apoiaram nossa crença de que a automação total tinha que ser nossa estrela-guia. Mesmo quando alguns fluxos de trabalho pareciam desafiadores ou arriscados para automatizar completamente, trabalhamos progressivamente em direção à automação total enquanto implementávamos a automação parcial no meio tempo. Essa abordagem nos permitiu implementar melhorias contínuas na confiabilidade do sistema e reduzir a sobrecarga operacional ao longo do tempo.
As operações permaneceram sem problemas e nenhum grande incidente durante e após o lançamento.
Novos recursos para melhores insights em tempo real
À medida que fizemos a transição para essa nova arquitetura, nossas capacidades de flexibilidade e automação melhoradas desbloquearam oportunidades para desenvolver novos recursos. Três melhorias principais melhoraram significativamente nossa experiência do usuário e a produtividade do desenvolvedor.
Frescor configurável
Com base no feedback dos usuários finais, definimos a frequência padrão para mesclar a cada três horas, para que pudéssemos equilibrar a atualização básica de todas as entidades com os custos de computação do Snowflake. Além disso, introduzimos substituições configuráveis para tabelas que requerem atualizações mais frequentes. Por exemplo, nosso pipeline de faturamento beneficiou-se significativamente de substituições de meia hora, o que reduziu consideravelmente a latência total de ponta a ponta do pipeline.
Sincronizar sob demanda
Podemos acionar mesclagens com segurança a qualquer momento graças ao nosso sistema de fila de tarefas de mesclagem. Essa segurança renovada nos permitiu introduzir uma ferramenta de CLI amigável ao usuário que possibilita a sincronização de dados manual e imediata fora do cronograma automatizado regular. Isso garante acesso oportuno a dados frescos do banco de dados online no Snowflake sempre que necessário.
Inspeção de dados do CDC no Snowflake
Como os dados do CDC já haviam sido importados para o Snowflake para fins internos, expusemos esses dados aos usuários finais interessados em obter insights mais profundos que explorassem a sequência de mudanças que levaram ao estado de uma entidade, não apenas o estado atual dessa entidade. Durante a resposta a incidentes, esse recurso fornece um ambiente offline seguro para depurar atividades inesperadas de gravação no banco de dados. Por exemplo, os desenvolvedores podem executar consultas como "recuperar todos os eventos de inserção/atualização/exclusão de e-mails para usuários dentro de uma equipe específica na última semana." Ao usar também nosso recurso para sincronizar sob demanda, os desenvolvedores podem consultar esses dados no Snowflake em quase tempo real. Para aderir a políticas de retenção de dados e prevenir o crescimento indefinido do armazenamento, os dados CDC são automaticamente eliminados após um período predefinido.
Resultados
Este projeto exigiu um investimento significativo de tempo, esforço e recursos – mas o trabalho valeu a pena, com resultados superando nossas expectativas.
Melhora na atualidade dos dados
Melhoramos dramaticamente a atualização de dados. Anteriormente, os dados frequentemente tinham 30 horas ou mais. Agora, os dados têm três horas ou menos, e os usuários têm a flexibilidade para configurar a atualização em minutos.
Desempenho escalável
Este pipeline agora lida de forma confiável com tabelas mais de dez vezes maiores do que antes, entregando desempenho consistente e previsível à medida que o Figma continua a crescer.
Produtividade do desenvolvedor
Novas ferramentas sempre têm o potencial de causar interrupções no fluxo de trabalho, então construímos confiança com nossa equipe ao entrevistá-los para identificar suas necessidades e integrar o pipeline com sistemas que nossa equipe já conhecia bem.
Uma vez que o trabalho foi concluído, conseguimos mostrar um aumento significativo na produtividade dos desenvolvedores, resultado da redução da sobrecarga operacional e do acesso quase em tempo real a dados online dentro do armazém de análise.
Os desenvolvedores agora podem consultar com segurança tanto o estado atual quanto o histórico de mudanças—atualizados em poucos minutos—impulsionando respostas a incidentes mais rápidas, lançamentos mais seguros e insights mais profundos.
Eficiência de custo
Logo no início da implementação, priorizamos o suporte para bancos de dados divididos horizontalmente. Esse suporte ofereceu um alto retorno sobre o investimento, pois os bancos de dados divididos horizontalmente tinham menos tabelas, mas utilizavam mais máquinas de banco de dados — cada uma com sua própria réplica de lote. Agora, esse pipeline proporciona economias anuais de milhões de dólares ao otimizar de forma inteligente a infraestrutura e a utilização de recursos, eliminando o processamento redundante e escalando de forma suave com o crescimento do negócio.
Oportunidades futuras
Nossa nova arquitetura estabelece a base para várias oportunidades promissoras de aprimorar e expandir ainda mais o pipeline de dados.
- Integração totalmente automatizada: Atualmente, a integração requer uma solicitação para adicionar tabelas a uma lista de permissão, o que cria atrito no processo de integração. Integrar nossa topologia de banco de dados diretamente no pipeline automatizaria totalmente a integração de tabelas, simplificando a experiência do desenvolvedor e reduzindo o esforço manual.
- Suporte a tabelas de ponto no tempo: Poderíamos fornecer a capacidade de realizar consulta dos estados das tabelas em qualquer posição de ponto no tempo dentro da nossa janela de retenção de CDC definida usando nossos dados de CDC. Implementar esse recurso melhoraria significativamente as capacidades de depuração, resposta a incidentes e flexibilidade analítica.
- Modelos incrementais atualizados: Muitos dos nossos modelos analíticos a jusante ainda são construídos usando processos tradicionais em lotes. Nosso novo pipeline nos permitiria atualizá-los incrementalmente, melhorando drasticamente sua eficiência e reduzindo a latência em todo o fluxo de trabalho analítico.
Esta transformação ambiciosa foi possível graças à incrível dedicação e esforço dos membros atuais e passados da equipe de Infraestrutura de Dados da Figma: Amadeo Casas, Alex Tian, Brandon Choi, Carter Bian, David Mah, Dorothy Chen, Ebuka Akubilo, Jimmy Xie, Krish Chainani, Merry Song, Michael Wu, Peng Wang, Raunak Agnihotri, Santosh Muthukrishnan, Xinxin Dai, Zubair Saiyed.
Agradecimentos e reconhecimento especial também são estendidos às nossas equipes parceiras de suporte: Asheesh Laroia, Dylan Visher, Gordon Yoon, Gustavo Angulo Mezerhane, Langston Dziko, Ping-Min Lin, Sammy Steele, Sean Rice, Yazad Khambata.

Estamos contratando engenheiros! Saiba mais sobre a vida no Figma econsulte nossas vagas abertas.