Soporte para tiempos de carga de archivos más rápidos con optimizaciones de memoria en Rust




La eficiencia de memoria es esencial para una gran experiencia de usuario. Para que los archivos funcionen rápidamente y tengan un buen rendimiento, el equipo de Figma siempre está buscando optimizaciones, aquí hay algunas.
Compartir Soporte para tiempos de carga de archivos más rápidos con optimizaciones de memoria en Rust
Ilustración principal de José Flores
El sistema multiusuario de Figma maneja la carga de archivos, la propagación de actualizaciones desde múltiples colaboradores, y el almacenamiento regular de instantáneas del estado del archivo. Para que la colaboración en tiempo real sea lo más rápida posible a través del complejo gráfico en un archivo de Figma, gran parte del archivo se carga en la memoria.
A medida que Figma crece, buscamos maneras de escalar eficientemente mientras conservamos una gran experiencia de usuario. Cuando lanzamos la carga dinámica de páginas, vimos un aumento del 30 % en la cantidad de archivos que necesitamos descodificar del lado del servidor. Para gestionar esta nueva carga, investigamos varias optimizaciones de rendimiento en Rust que resultaron en tiempos de carga más rápidos y en una eficiencia de memoria mejorada.
Mapas más pequeños y eficientes en memoria
Un archivo de Figma es conceptualmente una colección de nodos. Cada nodo representa algo diferente: un triángulo, un cuadrado, un marco, etc. Y cada nodo se puede considerar como un conjunto de propiedades que nos dicen cómo mostrarlo: su color, su forma, su principal, etc.


En el servidor, representamos los nodos como un mapa de claves (ID de propiedad) a valores, o Map<property_name (u16), property_value (u64 pointer)>, donde u16 y u64 se refieren al tamaño en bits de las entradas en el mapa.
Este mapa está en la ruta crítica para cargar un archivo, por lo que cualquier aceleración aquí se traduciría en tiempos de carga de archivos mejorados. Además, a través de algunos perfiles de memoria, descubrimos que este mapa era responsablede más del 60 % del uso de memoria de un archivo.(Dado que el mapa solo almacena metadatos y no datos, ¡nos sorprendió bastante este hallazgo!)
Así que examinamos esta estructura de datos en busca de potenciales optimizaciones. Estábamos usando el BTreeMap predeterminado en Rust, ya que nuestro protocolo de serialización necesitaba iteración ordenada. Después de observar el problema por un tiempo, nos dimos cuenta de que no necesitábamos todo el poder de un mapa genérico debido al pequeño rango en el que vivían nuestras claves.
El espacio de claves del mapa estaba limitado por nuevas propiedades que se agregaban a la definición de esquema de un archivo Figma, lo que ocurre a velocidades humanas, es decir, extremadamente lento. El esquema tiene menos de 200 campos hoy en día, y la mayoría de ellos aparecen en grupos. Por ejemplo, solo tendrías configurados los campos de comentario para un nodo de comentario, y no para ningún otro nodo. Al medir el número real de campos en algunos archivos de muestra, descubrimos que nuestra hipótesis era cierta, y el tamaño medio del mapa de propiedades era de alrededor de 60 claves.
Con esta conclusión, decidimos probar una disposición más simple y eficiente en cuanto a memoria: un vector plano y ordenado. Así, nuestra representación en memoria de un nodo pasó de:
BTreeMap<u16, pointer>{
0: 1, // node_id
1: FRAME, // type
2: null, // parent_id
... (x, y, w, h etc.)
},a:
Vec<u16, pointer>{
(0, 1),
(1, FRAME),
(2, null),
... (x, y, w, h)
}Una comparación rápida entre las dos representaciones, estilo Big O, nos dice que el enfoque basado en vectores es estrictamente peor desde una perspectiva de rendimiento:

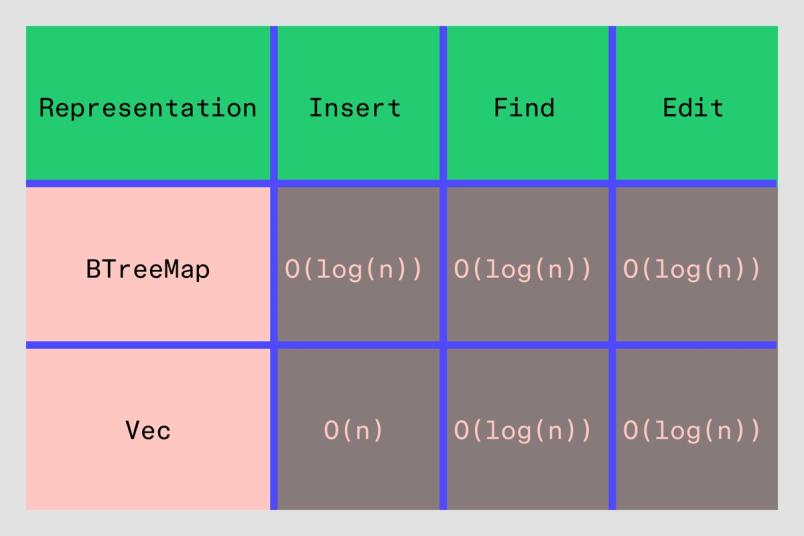
Sin embargo, esto ignora el hecho de que los ordenadores son especialmente rápidos cuando tienen que recorrer y realizar cálculos en pequeñas cantidades de memoria lineal (la configuración exacta aquí). Entonces, a pesar del tiempo de inserción teórico O(n) (si algo se inserta al comienzo del vector), esta solución fue más rápida al deserializar archivos (que es el proceso más importante para las cargas de archivos). En cuanto a nuestro uso de memoria, bueno, eso disminuyó casi un 25 % para archivos grandes: un éxito rotundo a escala.
Ahorro de más memoria con relleno de bits
Aunque terminamos implementando la solución anterior, también investigamos otra optimización que aún no se ha llevado a producción. Para explicar, necesitamos volver a centrarnos en el Map<u16, pointer> y preguntarnos: ¿Qué es realmente un puntero?
Los punteros son solo 64 bits de datos que le dicen a su CPU vecina y amigable dónde puede encontrar el inicio de otro dato. 64 bits de datos corresponden a 2^64 bytes o 18 exabytes de memoria direccionable, una cantidad a la que nuestro sistema multiusuario nunca tendría acceso. De hecho, la mayoría de los procesadores x86 están de acuerdo en que no necesitas tanta memoria, por lo que un puntero en x86 realmente se ve así:
[0u16, pointer_u48]Los 48 bits inferiores del puntero son la única parte utilizada para direccionar la memoria (aunque esto no es una garantía, y podría cambiar en el futuro), ¡y los 16 bits superiores son libres para que los usemos!
Por algún feliz accidente, nuestro Map<u16, pointer> necesita exactamente 16 bits adicionales de datos para almacenar el ID de campo, y así podemos llenar nuestros punteros con el ID de campo para almacenar tanto el ID de campo como el puntero en un único número de 64 bits. Nuestra representación de datos ahora se ve así:
Vec<u64>{
[0_u16 type_ptr_u48],
[1_u16, FRAME_ptr_u48],
... (x, y, w, h)
}
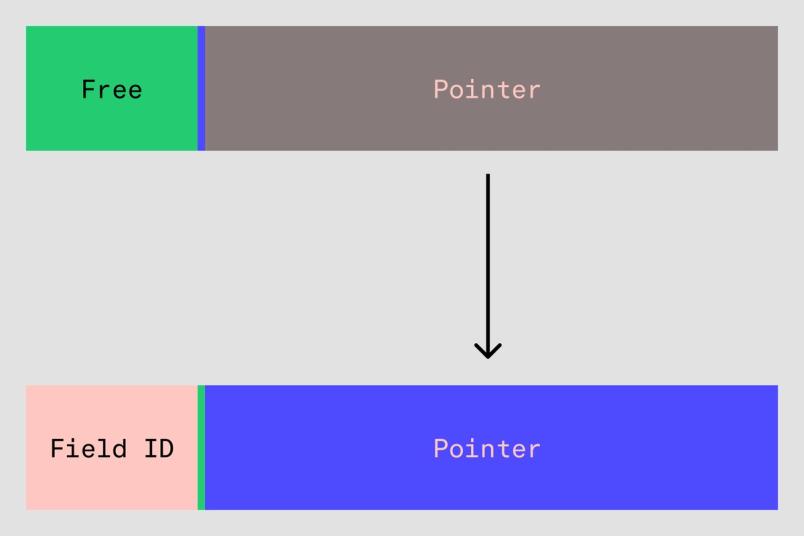
Utilizamos algunas operaciones simples de bits para obtener la ID de campo y el puntero del número de 64 bits. La implementación en Rust de esto requiere que manejemos cuidadosamente el ciclo de vida de estos punteros. Dado que usamos punteros contados por referencia, debemos asegurarnos de que los contadores de referencia se actualicen correctamente en insertar o adquirir para evitar la corrupción de memoria.
El tamaño del conjunto residente es la cantidad de memoria que un proceso está consumiendo en la RAM (memoria principal).
Este enfoque resultó en un rendimiento ligeramente más rápido en la prueba de rendimiento, y un uso de memoria ligeramente menor (aproximadamente 5 % menos que el enfoque de vector simple). Esperábamos un ahorro de memoria mayor ya que, ingenuamente, la nueva representación debería estar usando exactamente un 20 % menos de datos. Sin embargo, la métrica de memoria que realmente nos importa es el tamaño del conjunto residente (RSS, por sus siglas en inglés), que no siempre corresponde directamente con la memoria asignada y depende del comportamiento del asignador subyacente y del sistema operativo.
Decidimos no poner en producción esta optimización por la simple razón de que la ganancia extra no parecía valer la pena los potenciales inconvenientes de memoria a los que nos exponíamos, pero siempre es una palanca que tenemos para el futuro.
Los números bajan
Usar un vector en lugar de un mapa para representar archivos de Figma en Rust ha acelerado los tiempos de carga de archivos para nuestros usuarios. Por instancia, mejoró los tiempos de deserialización de archivos en un 20 % en el percentil 99, ¡los archivos de Figma más lentos ahora se cargan más rápido! Y este pequeño cambio también nos ahorró un 20 % en costos de memoria en toda nuestra flota multiusuario.
Siempre estamos buscando hacer que nuestra tecnología multiusuario sea más eficiente, con mayor rendimiento y más fácil de ejecutar con optimizaciones como esta. Si este tipo de trabajo te interesa, consulta nuestras vacantes abiertas: ¡estamos contratando!