Visibilidad a gran escala: cómo Figma detecta la exposición de datos confidenciales



Resolver los retos de seguridad a gran escala requiere tanto creatividad como rigor. Para reducir el riesgo de exposición de datos confidenciales, hemos creado un muestreo de respuestas: un control sencillo y en tiempo real que supervisa las respuestas salientes, valida el acceso y proporciona un sistema de alerta temprana en todos nuestros productos.
Compartir Visibilidad a gran escala: cómo Figma detecta la exposición de datos confidenciales
Ilustraciones de Jose Flores
Prevenir la exposición de datos confidenciales mediante programación es uno de los retos más complejos de la ingeniería de seguridad. La naturaleza de los sistemas modernos y distribuidos implica que los datos pueden viajar por rutas intrincadas y, en ocasiones, impredecibles, a través de servicios, capas de serialización y contextos en los que su presencia no siempre es evidente. Este tipo de problemas pueden manifestarse de formas sutiles: un terminal que devuelve más datos de los previstos, una ruta de código heredada que omite una comprobación de permisos o una validación que falta y que permite a los usuarios ver recursos que no deberían. En términos de seguridad, a menudo se trata de fallos de autorización o de una sobreexposición involuntaria de datos, pequeños errores que pueden tener un impacto desmesurado en la privacidad y la confianza a gran escala.
Para abordar este reto de frente en Figma, necesitábamos crear un sistema de supervisión que actuara como red de seguridad y como sistema de alerta temprana, detectando las exposiciones en el entorno de pruebas antes de que llegaran a la producción y continuando con la vigilancia de regresiones inesperadas una vez implementado. Esto significaba crear algo lo suficientemente preciso como para ser fiable y lo suficientemente amplio como para ser valioso en muchos componentes diferentes del producto.
Nos complace compartir nuestra experiencia en la creación del muestreo de respuestas, un sistema diseñado para detectar posibles fugas de datos confidenciales en tiempo real. Al proporcionar una visibilidad continua de los datos que salen de nuestros servicios, el muestreo de respuestas ofrece a nuestros equipos la oportunidad de investigar y resolver problemas rápidamente, lo que reduce el riesgo de exposición y mejora nuestra confianza en la forma en que se gestionan los datos.
Abordamos este problema con una mentalidad centrada en la seguridad de la plataforma, tratando las superficies de nuestras aplicaciones como infraestructura y aplicando controles continuos de supervisión y detección. Al aplicar técnicas que normalmente se reservan para sistemas de nivel inferior a nuestra capa de aplicaciones, pudimos obtener una visibilidad continua de cómo se mueven los datos a través de nuestros productos, sin ralentizar el desarrollo.
Identificación del problema: visibilidad de las exposiciones ocultas
En Figma, nos tomamos los permisos y las autorizaciones muy en serio. A lo largo de los años, hemos invertido en controles preventivos sólidos, como PermissionsV2, nuestro marco de autorización detallado, así como en pruebas continuas mediante pruebas unitarias negativas, pruebas integrales en entornos de prueba y producción, y programas de revisión de seguridad continuos (incluido nuestro programa de recompensa por bug y pruebas de penetración periódicas). Estos sistemas nos transmiten una gran confianza en nuestros límites de acceso y constituyen la base de cómo evitamos la exposición de datos confidenciales.

Lee más sobre cómo creamos PermissionsV2.
La exposición de datos confidenciales es una vulnerabilidad de seguridad mediante la cual información confidencial o protegida se pone involuntariamente a disposición de personas que no deberían tener acceso a ella, lo que crea un riesgo de uso indebido o pérdida de confianza.
Pero las medidas preventivas y las pruebas por sí solas no pueden detectar todos los casos extremos. A medida que nuestros productos e infraestructura se han vuelto más complejos, el riesgo de descuidos sutiles o flujos de datos inesperados ha aumentado naturalmente. Incluso los sistemas bien diseñados pueden dar sorpresas cuando los servicios interactúan de maneras nuevas o cuando las rutas existentes se comportan de forma diferente a lo esperado.
Dada la importancia que tiene la protección de datos para Figma, queríamos añadir otra capa de defensa, centrada en la detección y la capacidad de observación. Nuestro objetivo era crear un sistema que pudiera validar continuamente que nuestros controles preventivos funcionaban según lo previsto y nos ayudara a detectar anomalías de forma temprana, antes de que pudieran afectar a la producción.
Para que eso fuera posible, necesitábamos un sistema que pudiera:
- Supervisar continuamente las posibles exposiciones, independientemente del lugar del producto en el que se produjeran.
- Proporcionar datos prácticos que nos permitieran solucionar los problemas temprano, idealmente antes de que llegaran a la producción.
- Mantenerse activo en la producción como una capa adicional de defensa para detectar regresiones en tiempo real.
Estos objetivos conformaron la base de nuestro enfoque y sirvieron de guía para equilibrar el alcance de la detección, el impacto en el rendimiento y el mantenimiento operativo.
Paso 1: creación del muestreo de respuestas para identificadores de archivos
Antes de poder detectar la exposición de datos confidenciales mediante programación, primero había que decidir qué se consideraba confidencial. No todos los campos en una respuesta de API suponen un riesgo, por lo que empezamos con un tipo bien definido, los identificadores de archivos, en los que la confidencialidad y las reglas de acceso ya estaban claras. Los identificadores de archivos en Figma son tokens únicos incrustados en la URL de cada archivo que lo vinculan a controles de acceso específicos. Dado que son tokens de alta entropía con un conjunto de caracteres conocido y una longitud consistente, los identificadores de archivos son fáciles de detectar en flujos de texto. Eso los convirtió en un punto de partida práctico para detectar bugs de autorización y crear la infraestructura que más adelante permitiría realizar un muestreo de respuestas más amplio, una vez que se dispusiera de una definición sistemática de los datos confidenciales.

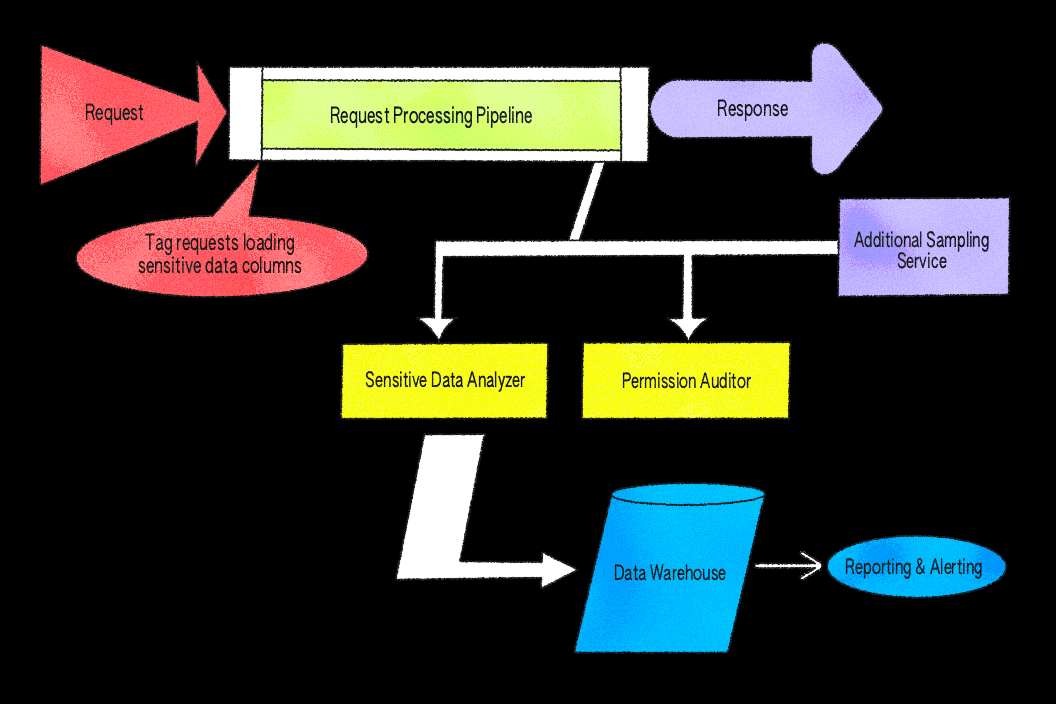
Nuestra implementación inicial se centró en este tipo de datos y en las verificaciones de permisos asociadas. La idea era sencilla, pero eficaz: tomar una pequeña muestra de respuestas de servicios clave, buscar identificadores vinculados a archivos y verificar que el usuario solicitante tuviera permiso para acceder a cada valor. El muestreo se realiza de forma aleatoria y uniforme, con una tasa configurable en todas las rutas de solicitud, lo que nos permite controlar la cobertura y limitar la sobrecarga, mientras seguimos obteniendo resultados representativos.
Creamos el sistema como middleware en nuestro servidor de aplicaciones Ruby porque proporciona acceso directo al objeto de usuario autenticado, al cuerpo completo de la respuesta de API y a nuestro sistema de permisos interno, PermissionsV2. Esto facilita la inspección de los datos de respuesta y la evaluación de los permisos en un solo lugar. Aunque podríamos haber implementado verificaciones similares en una capa proxy, como Envoy, hacerlo habría dificultado considerablemente la realización de las evaluaciones de permisos según el contexto del usuario que requiere nuestra arquitectura.
Implementamos el muestreo de respuestas utilizando un bloque after y trabajos asíncronos. El filtro after es un gancho integrado que se ejecuta automáticamente tras completarse cada solicitud, permitiéndonos inspeccionar las respuestas de forma sistemática antes de que se envíen al cliente. El filtro inspecciona las respuestas elegibles según las tasas de muestreo configuradas y analiza los cuerpos JSON para extraer los identificadores de archivo. Cuando se encuentra un identificador relevante, el sistema pone en cola trabajos asíncronos para verificar los permisos. Para reducir los falsos positivos, la lógica de verificación aplica reglas que tienen en cuenta los casos seguros conocidos, de modo que solo se muestran los resultados inesperados, que se someten a revisión. Todo esto se realiza sin bloqueos: si el muestreo o la verificación fallan, la solicitud se completa normalmente y los errores se registran para su supervisión.
Un terminal interno permite que otros servicios, como LiveGraph, nuestro servicio de obtención de datos en tiempo real que mantiene sincronizadas las experiencias de colaboración, envíen sus propios datos de muestreo y reutilicen el canal de procesamiento. Después de generar una respuesta, LiveGraph realiza una llamada API sencilla a este terminal, lo que te permite beneficiarte del muestreo de respuestas sin añadir sobrecarga a su flujo de datos en tiempo real. Para mantener un rendimiento predecible, el muestreo en LiveGraph se regula mediante la configuración y la limitación de la velocidad. Los hallazgos comparten el mismo esquema y la misma ruta de registro que otros servicios, por lo que los resultados se unifican en nuestro almacén de análisis y paneles de triaje, de modo que los ingenieros de guardia pueden interpretar fácilmente las alertas independientemente de su origen.

Lee más sobre cómo creamos LiveGraph.
Incorporamos esta lógica directamente en nuestra infraestructura API, de modo que se pudiera ejecutar tanto en el tráfico del entorno de pruebas como en el de producción. Las tasas de muestreo se ajustaron para capturar la cobertura suficiente para obtener resultados significativos sin introducir una latencia apreciable, y todas las verificaciónes se realizaron de forma asíncrona para evitar ralentizar el ciclo de solicitud-respuesta. Además, se estableció una limitación de la tasa para evitar la sobrecarga del canal de procesamiento y el consumo excesivo de recursos.
Este enfoque comenzó a revelar inmediatamente datos valiosos. A los pocos días de su implementación, el muestreo de respuestas sacó a la luz casos sutiles en los que se devolvían innecesariamente identificadores relacionados con archivos en determinadas respuestas, lo que dió lugar a un mejor filtrado de datos. También reveló rutas en las que determinados archivos eludían por completo los controles de permisos, por lo que pudimos cerrar esas brechas y reforzar nuestros controles de acceso en general.
El primer paso demostró la viabilidad del concepto, pero su alcance era limitado. Los identificadores de archivos son importantes, pero solo representan una categoría de la información confidencial que necesitamos proteger.
Paso 2: aumentar la visibilidad con un muestreo de respuestas ampliado
Una vez sentadas las bases, nos propusimos ampliar el alcance del sistema. La implementación inicial demostró que el muestreo de respuestas podía detectar problemas de autorización reales de manera eficiente, pero se limitaba a un solo tipo de datos. El siguiente reto consistía en ampliar el mismo enfoque a cualquier campo confidencial, es decir, enseñar al sistema a reconocer el significado de “confidencial” en todos nuestros productos.
El muestreo de respuestas ampliado, conocido internamente como ’muestreo de respuestas sofisticado’, extendió los mismos principios de muestreo a todos los datos confidenciales al integrarse con FigTag, nuestra herramienta interna de categorización de datos.

FigTag funciona anotando cada columna de la base de datos con una categoría que describe su confidencialidad y el uso previsto. Estas anotaciones se almacenan en un esquema central y se propagan a nuestro almacén de datos, por lo que es fácil determinar la confidencialidad de una columna en el momento de la consulta. Una de estas categorías, banned_from_clients, actúa como nuestra señal de confidencialidad, marcando los campos que no deben devolverse en las respuestas de API en circunstancias normales (por ejemplo, identificadores relacionados con la seguridad, detalles de facturación y otra información de identificación personal).
Al integrarnos con FigTag, podemos obtener muestras de un subconjunto de respuestas que contienen cualquier campo confidencial, en todos los terminales de la API de nuestro servidor de aplicaciones. Cuando un registro de la base de datos con una columna etiquetada como banned_from_clients se carga en la aplicación (en nuestro caso, a través de un modelo ActiveRecord, la capa de mapeo objeto-relacional utilizada en nuestra aplicación Ruby), una devolución de llamada registra su valor en el almacenamiento local de la solicitud. Para las solicitudes de muestra, esto garantiza que solo se haga un seguimiento de los valores a los que realmente se ha accedido durante la solicitud, evitando una sobrecarga innecesaria.
Una vez generada la respuesta, un filtro after inspecciona el JSON serializado y lo compara con los valores confidenciales registrados. Si aparece algún valor confidencial en la respuesta, se registra un hallazgo. Como antes, los resultados pasan a nuestro almacén de análisis unificado y nuestros paneles.
También introdujimos un proceso flexible de listas de permitidos, de modo que los terminales con exposición intencionada y segura puedan excluirse del muestreo de respuestas sin sacrificar la detección de datos verdaderamente inesperados. Por ejemplo, un secreto de cliente OAuth podría devolverse intencionadamente desde un terminal de gestión de credenciales dedicado para usuarios autorizados, pero sería un problema grave si se incluyera en respuestas de API no relacionadas.
La detección precoz en acción
El sistema de muestreo de respuestas ampliado se ha convertido en una potente capa de detección, que saca a la luz problemas sutiles que habrían sido extremadamente difíciles de detectar solo mediante la revisión del código o el control de calidad manual. Nos ha permitido detectar de forma proactiva los riesgos en el entorno de pruebas y responder rápidamente a las regresiones de producción. Aquí hay algunos ejemplos:
- Detectamos que un campo de datos que llevaba mucho tiempo sin utilizarse aparecía inesperadamente en ciertas respuestas. El equipo confirmó el hallazgo, lo categorizó y envió una solución específica rápidamente.
- El sistema detectó casos en los que se incluían datos de recursos relacionados en las respuestas sin que existiera una necesidad clara, lo que dio lugar a una labor de depuración específica.
- El muestreo de respuestas puso de relieve situaciones en las que se devolvía una lista de recursos en una respuesta sin verificar el acceso a cada elemento individualmente, lo que dio lugar a mejoras en las verificaciones de permisos.
Lecciones aprendidas sobre cómo equilibrar precisión y rendimiento
La creación de sistemas como este es un esfuerzo conjunto de varios equipos en Figma. Nuestros ingenieros de seguridad envían código junto con los equipos de producto y plataforma, aportando la misma creatividad y rigor a los sistemas de detección que a las funciones orientadas al usuario.
Tras meses de crear y ejecutar el muestreo de respuestas, hemos aprendido mucho sobre los requisitos para crear un sistema de detección programático:
- Piensa siempre en el impacto en el rendimiento: hemos descubierto que incluso pequeñas cantidades de supervisión pueden introducir latencia si no se diseñan con cuidado. Al ajustar las tasas de muestreo y ejecutar comprobaciones de forma asíncrona, mantuvimos el rendimiento para los usuarios y, al mismo tiempo, obtuvimos una visibilidad significativa del tráfico.
- Gestiona los falsos positivos (¡o te gestionarán a ti!): Una tasa elevada de falsos positivos puede abrumar a los equipos y reducir la confianza en las alertas. Para abordar este problema, implementamos una lista de permitidos dinámica y flujos de trabajo de triaje rigurosos. Esto supuso filtrar rápidamente los casos que sabíamos que eran seguros y permitir a los ingenieros centrarse en los hallazgos realmente peligrosos.
- El contexto importa: no todas las exposiciones de datos confidenciales son igualmente problemáticas. Mediante la configuración dinámica, pudimos ajustar rápidamente las reglas de detección sin necesidad de volver a implementar los servicios. Esto permitió un manejo matizado de los casos prácticos legítimos, mientras que se seguían señalando los escenarios anormales o inesperados.
- Crea una defensa por capas: ejecutar el sistema tanto en el entorno de pruebas como en el de producción nos proporcionó dos líneas de defensa: la detección temprana antes del lanzamiento y la supervisión continua para detectar regresiones. Este enfoque de defensa en profundidad ha sido fundamental para mantener la resiliencia a largo plazo.

El camino a seguir
Con el muestreo de respuestas, hemos aplicado un enfoque de seguridad de plataforma a la seguridad del producto, superponiendo monitoreo y detección continuos sobre nuestras superficies de aplicación para detectar problemas temprano sin ralentizar el desarrollo.
Estamos ampliando este marco para abarcar más servicios y otros puntos de contacto con los usuarios, de modo que podamos identificar la exposición potencial en todos los principales canales de interacción. También tenemos previsto ampliar la cobertura a otras categorías de datos confidenciales, incluidas clases más amplias de información de identificación personal y datos regulados, para garantizar que nuestras capacidades de detección escalen con las necesidades de cumplimiento normativo en constante evolución.
Para mantener la eficacia del muestreo de respuestas a medida que nuestros sistemas crecen, estamos explorando formas de hacerlo más adaptable y detallado. Por ejemplo, estamos investigando controles de muestreo más precisos para equilibrar el uso de recursos con la visibilidad, el triaje automatizado para acelerar las investigaciones y la elaboración de Informes más completos para detectar tendencias a lo largo del tiempo. A medida que ampliamos este marco, nuestro objetivo sigue siendo el mismo: proteger los datos de los usuarios y garantizar que cada experiencia de Figma siga siendo rápida, fiable y segura.
Los equipos de AppSec no suelen adoptar enfoques de seguridad de infraestructura, pero la creación del muestreo de respuestas demostró lo eficaces que pueden ser cuando se aplican en la capa de aplicación. Acercar la detección continua a la capa de aplicación nos ayudó a detectar problemas antes y a responder más rápidamente, un enfoque del que creemos que otros equipos podrían beneficiarse si lo adoptaran.

¡Estamos contratando ingenieros! Obtén más información sobre cómo es trabajar en Figma, y consulta nuestras vacantes.