



D'une latence de plusieurs jours à des informations quasi en temps réel : la mise à niveau du pipeline de données de Figma




Après une croissance exponentielle des utilisateurs et données, la synchronisation nécessite des heures. Recréer un pipeline réduit la latence au temps réel.
Partager D'une latence de plusieurs jours à des informations quasi en temps réel : la mise à niveau du pipeline de données de Figma
Illustrations par Cynthia Alfonso
Au cours des cinq dernières années, Figma a connu une croissance rapide, dont le lancement de FigJam en 2021, de Dev Mode en 2023 et de Figma Make en 2025, et une localisation complète pour desservir les marchés brésilien, japonais, espagnol et coréen – mais cette croissance s'accompagne de défis. Le volume et la complexité des données générées par notre plateforme ont augmenté chaque jour, parallèlement à l'élargissement de notre base d'utilisateurs.
L'année dernière, nous avons raconté comment notre équipe des bases de données a horizontalement mis à l'échelle nos bases de données relationnelles en ligne. Mais notre système de synchronisation hérité, responsable du transfert des données de nos bases de données en ligne vers notre entrepôt analytique, et qui alimente des informations commerciales cruciales, y compris les indicateurs clés de performances de l'entreprise, a eu du mal à suivre le rythme.

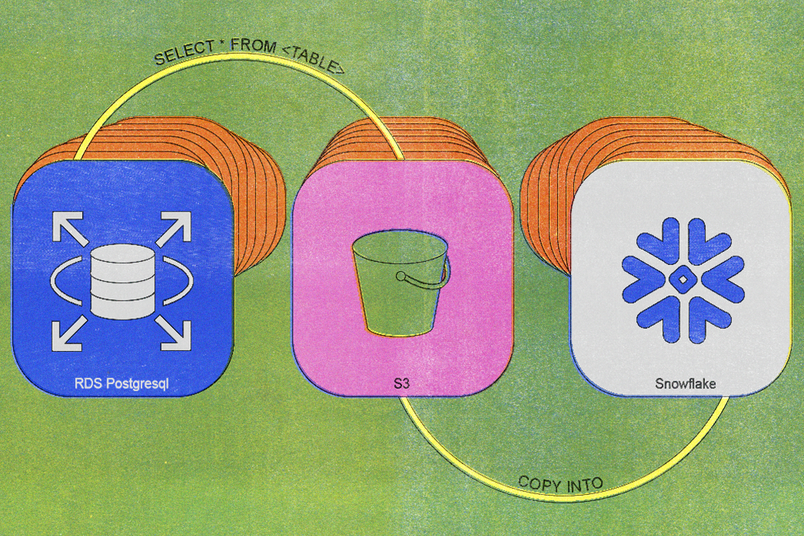
Nous avons conçu notre premier processus de synchronisation hérité en 2020, et l'architecture était simple : un travail cron quotidien exécutait une requête SELECT * FROM <TABLE> simple, téléchargeait les données résultantes sur S3 et importait ces données dans Snowflake.
Au départ, cela fonctionnait bien. Cependant, les tables gagnant en taille et nécessitant de plus en plus d'insertions, les limitations du système sont devenues évidentes. En 2023, les tâches de synchronisation quotidienne nécessitaient environ six heures et nous devions gérer des réplicas de base de données supplémentaires pour prendre en charge les exportations quotidiennes. Nos plus grandes tables connaissaient des temps de synchronisation de plusieurs jours ou plus.
Finalement, il fut presque impossible de synchroniser nos données dans un délai raisonnable, ce qui entrava sévèrement notre capacité à analyser les données et à prendre des décisions éclairées.
Nous avons évalué trois solutions :
- Conserver notre processus de synchronisation hérité : cette solution est rapidement devenu impossible, à la fois en raison des délais de synchronisation et parce que la gestion de réplicas supplémentaires de la base de données se traduisait par des millions de dollars de coûts inutiles chaque année.
- Ajouter un parallélisme comme solution rapide : nous avons envisagé d'ajouter un parallélisme, qui aurait permis au processus de synchronisation d'exécuter des opérations de manière simultanée, mais cela s'est avéré peu évolutif.
- Remanier complètement le processus de synchronisation des données : cela nécessiterait un investissement plus important sur une période de temps plus longue, mais ce serait l'approche la plus évolutive et la plus susceptible de durer parallèlement au développement de Figma.
La synchronisation incrémentielle est une technique de pipeline de données conçue pour maintenir efficacement les bases de données analytiques à jour en ne capturant et en n'appliquant que les changements récents de la base de données source, au lieu de transférer plusieurs fois des ensembles de données entiers. Cela réduit considérablement le temps de transfert de données et l'utilisation des ressources.
Après un examen des options, notre choix est devenu clair : nous nous sommes orientés sur le long terme et avons commencé à travailler sur la synchronisation incrémentielle – une solution promettant des résultats durables et efficaces.
Acheter et concevoir
Pour fonctionner, la synchronisation incrémentielle nécessite la prise en charge des instantanés de table de base de données, des flux de capture de données de changement (CDC) et de la fusion incrémentielle. Plus nous examinions le potentiel de la synchronisation incrémentielle, plus nous constations qu'il nous fallait la concevoir nous-mêmes. Nous avons envisagé d'acheter une solution propriétaire complète, mais aucune option ne répondait à nos besoins en termes de flexibilité, de coûts et d'échelle.
Flexibilité : de nombreux outils compatibles avec SQL génériques que nous avons trouvés n'utilisaient pas efficacement les capacités spécifiques aux vendeurs. Les API d'Amazon Relational Database Service (RDS) pour PostgreSQL, par exemple, nous auraient permis de produire des instantanés directement sans le surcoût lié à la gestion d'un réplica de base de données séparée, mais les options génériques n'en tiraient pas parti. En optant pour une solution fournisseur, nous n'aurions pas la flexibilité nécessaire pour optimiser notre workflow en fonction de notre technologie.
Coût : de nombreuses options auraient également coûté significativement cher à notre échelle. En évaluant nos options, nous avons projeté que les solutions propriétaires coûteraient cinq à dix fois plus qu'une solution interne.
Échelle : le coût aurait pu en valoir la peine si ces outils pouvaient évoluer, mais nous avons constaté que beaucoup n'étaient pas assez évolutifs par rapport à nos besoins actuels et croissants. Nous avons conçu notre processus de synchronisation hérité en 2020, et Figma continue de croître. En concevant en interne, nous sommes sûrs de pouvoir innover rapidement en réponse aux besoins futurs.
Concevoir et combiner des composants de niveau inférieur
En concevant un pipeline sur mesure, nous avons pu trouver et combiner des composants de niveau inférieur – des services open-source ou gérés – correspondant exactement à nos exigences d'infrastructure (et à l'expertise de notre équipe).
Pour les instantanés, nous utilisons Amazon RDS, qui peut exporter vers S3 dans le cas des copies de tables initiales. Pour la capture de données de changement (CDC), nous utilisons Kafka Connect, qui offre un streaming efficace une fois intégré à un connecteur Snowflake et hébergé sur Amazon Managed Streaming pour Apache Kafka (MSK). Pour la fusion incrémentielle, nous avons mis en œuvre une logique de fusion personnalisée à travers des procédures stockées Snowflake et des processus automatisés via les tâches Snowflake.
Concevoir une nouvelle architecture de pipeline
Avec chaque projet nouveau, nous esquissons les principes de design qui orientent le travail, façonnant nos objectifs et nos décisions. Pour ce projet, nous avons défini quatre principes :
- Latence : réduire le temps de synchronisation des données de bout en bout.
- Coût : réduire les coûts et les maintenir à un niveau bas même si nous continuons à nous développer.
- Conformité : maintenir la conformité avec toutes les normes réglementaires de données pertinentes.
- Intégrité des données : utiliser des workflows qui garantissent que les données demeurent précises, complètes, cohérentes et fiables tout au long du cycle de vie.

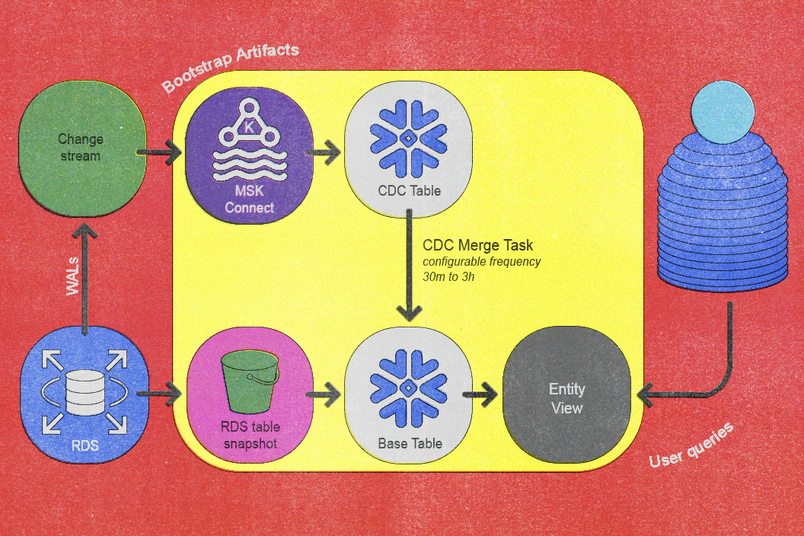
En fin de compte, ces principes se sont traduits par un pipeline de données réimaginé qui opère une synchronisation incrémentielle via deux workflows fondamentaux : un workflow d'initialisation et un workflow de validation. Le workflow d'initialisation intègre de nouvelles tables dans le pipeline et le workflow de validation vérifie l'exactitude des données à mesure qu'elles circulent dans le flux du pipeline. Ensemble, ces deux workflows garantissent que les données circulent efficacement et demeurent aussi cohérentes et correctes que possible.
Flux d'initialisation
Notre processus d'intégration des nouvelles tables dans le pipeline de synchronisation se compose des étapes automatisées et clairement définies suivantes :
- Le service CDC existant capture la nouvelle table de Postgres et publie des événements dans les rubriques par table de Kafka. Nous avons automatisé cette étape à l'aide de notre service CDC interne existant et l'avons intégrée à la topologie du système de base de données.
- Nous transférons le dernier instantané quotidien de la base de données vers S3 à l'aide du processus d'exportation d'instantané d'Amazon RDS (qui peut être long, selon la taille de la table).
- Une fois l'instantané exporté vers S3, la requête
COPY INTO <table>de Snowflake importe les données de S3 dans les tables de base par entité dédiées de Snowflake. - Un connecteur Sink Snowflake au sein de MSK Connect transmet le contenu des rubriques Kafka dans les tables CDC par entité de Snowflake, garantissant que le décalage de départ de Kafka précède l'horodatage de l'instantané.
- Nous programmons une tâche Snowflake pour exécuter périodiquement une procédure stockée
MERGEpersonnalisée que nous avons développée. - Lorsque la synchronisation rattrape suffisamment les changements récents, nous créons une vue légère au-dessus de la table de base pour rendre l'interrogation par les utilisateurs facile, ce qui complète l'intégration.
Nous avons mis en œuvre une fonctionnalité de réinitialisation sans interruption, cruciale pour gérer des événements tels que l'évolution du schéma. Pour cela, nous avons versionné tous les artefacts d'initialisation à l'exception de la vue orientée utilisateurs finale, ce qui permet une initialisation parallèle sans perturber les opérations en direct. La promotion vers la nouvelle version se fait sans heurts via une étape de mise à jour de la vue atomique.
Workflow de validation
En dépit de designs robustes, les pipelines de données risquent inévitablement une corruption des données en cas de défaillances partielles, de composants mal configurés, de bugs logiciels ou d'anomalies inattendues des données sources. Des problèmes peuvent apparaître à différents moments – des exportations d'instantanés et des captures d'événements CDC aux fusions incrémentielles – et peuvent entraîner des incohérences silencieuses des données ou des résultats analytiques incorrects s'ils ne sont pas examinés.
Par conséquent, un autre aspect critique de l'architecture réside dans un workflow de validation robuste dédié à la vérification de l'exactitude des données, qui fonctionne comme suit :
- Clonez la table de base en direct, que nous désignons comme source.
- Exécutez le workflow d'initialisation, que nous avons explicitement configuré pour exporter les tables de base et CDC dans un schéma temporaire, désigné comme cible. Ce workflow s'exécute sans initialiser de fusions automatisées.
- Alignez les tables de base source et cible sur les mêmes positions à un instant donné à l'aide des données CDC exportées pour garantir la cohérence.
- Effectuez des comparaisons précises, de cellule à cellule, entre les tables source et cible.
- Générez des résultats détaillés à partir de ces comparaisons et intégrez les résultats dans nos systèmes de surveillance et d'alerte.
Cette validation rigoureuse, au niveau cellulaire et compatible avec la capture de données de changement (CDC), apporte une confiance absolue dans l'intégrité des données, ce qui améliore considérablement la fiabilité avant et après le lancement du service.
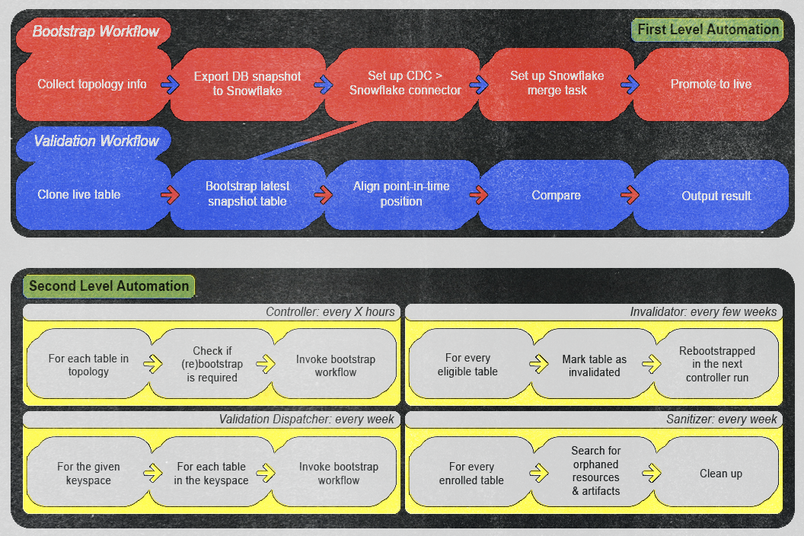
Investir dans l'automatisation
Ici, la réussite ne serait pas possible sans automatisation. Le pipeline que nous avons conçu nécessitait une orchestration étendue à travers une quantité d'appels et de dépendances réseau, et nous avions besoin d'une automatisation ad hoc et programmée pour tout mettre en place.
À l'aide d'AWS Step Functions, nous avons organisé notre automatisation en deux catégories :
Automatisation de premier niveau : cette catégorie inclut les workflows pouvant être utilisés manuellement et de manière ad hoc. Nous avons conçus ces workflows pour exécuter des processus d'initialisation ou de validation en ne fournissant que le nom de l'entité. Une fois exécutés, ils ne nécessitent aucune intervention manuelle, sauf si la surveillance génère une alerte. Nous avons fait en sorte que les alertes soient assez fortes pour inciter une action immédiate de l'opérateur, qu'il s'agisse d'un bug réel dans le pipeline ou d'un faux positif dans la logique de validation, et pour fournir des actions claires afin d'éviter toute récurrence et de maintenir une efficacité et une fiabilité opérationnelles élevées.
Automatisation de second niveau : cette catégorie inclut des workflows que nous avons conçus pour invoquer des automatisations de premier niveau en fonction de conditions et de calendriers spécifiques. Le premier niveau effectue le gros du travail, tandis que le second niveau vérifie automatiquement les états actuels pour établir s'il faut déclencher une automatisation de premier niveau. Les exemples incluent :
- Un workflow de contrôleur recherche régulièrement toutes les quelques heures les nouvelles entités disponibles pour l'intégration ou la réinitialisation.
- Un workflow de répartition de validation initie automatiquement des workflows de validation pour chaque table sur une base hebdomadaire.
- Un workflow d'invalidation effectue des opérations de réinitialisation hebdomadaires sur chaque table pour garantir l'intégrité des données.
- Un workflow de désinfection nettoie régulièrement chaque semaine les artefacts potentiellement orphelins, maintenant un environnement propre et efficace.

Nous avons adopté une approche agressive des tests : une routine rigoureuse d'automatisation dans notre environnement de préproduction réinitialise automatiquement toutes les tables chaque semaine pour simuler et identifier proactivement les problèmes potentiels. Cela a porté ses fruits lorsque nous avons identifié un mode de défaillance sévère dès la première semaine de tests. Ce problème aurait entraîné une panne à l'échelle du site qui aurait duré au moins vingt minutes s'il avait touché la production. En détectant cette situation tôt, nous avons assuré la stabilité lors des déploiements en production réelle.
Des cas tels que celui-ci soutenaient notre conviction que l'automatisation complète devait être notre repère. Même lorsque certains workflows semblaient difficiles ou risqués à automatiser complètement, nous avons progressivement œuvré vers une automatisation complète tout en mettant en œuvre une automatisation partielle dans l'intervalle. Cette approche nous a permis d'apporter des améliorations régulières à la fiabilité du système et de réduire les frais d'exploitation au fil du temps.
Les opérations sont restées fluides et aucun incident majeur n'a été signalé pendant et après le lancement.
Nouvelles fonctionnalités pour de meilleures informations en temps réel
À mesure que nous adoptions cette nouvelle architecture, notre flexibilité améliorée et nos fonctionnalités d'automatisation se sont traduites par des opportunités de développer de nouvelles fonctionnalités. Trois améliorations clés ont significativement amélioré notre expérience utilisateur et la productivité des développeurs.
Fraîcheur configurable
Sur la base du feedback des utilisateurs finaux, nous avons défini la fréquence de fusion par défaut sur toutes les trois heures afin de pouvoir équilibrer la fraîcheur de base de toutes les entités par rapport aux coûts de calcul Snowflake. De plus, nous avons introduit des dérogations configurables pour les tables nécessitant des mises à jour plus fréquentes. Par exemple, notre pipeline de facturation a bénéficié de manière significative des dérogations de trente minutes, ce qui a considérablement réduit la latence globale du pipeline.
Synchronisation à la demande
Nous pouvons déclencher des fusions en toute sécurité à tout moment grâce à notre système de mise en file d'attente des travaux de fusion. Cette sécurité renouvelée nous a permis d'introduire un outil CLI convivial pour l'utilisateur qui permet une synchronisation des données manuelle et immédiate en dehors du calendrier automatisé régulier. Cela garantit un accès en temps réel aux données fraîches de la base de données en ligne dans Snowflake chaque fois que nécessaire.
Inspection des données CDC dans Snowflake
Étant donné que les données CDC avaient déjà été importées dans Snowflake à des fins internes, nous avons présenté ces données aux utilisateurs intéressés par des informations plus approfondies qui explorent la séquence de changements ayant conduit à l'état d'une entité, et pas uniquement l'état actuel de cette entité. Lors de la réponse aux incidents, cette fonctionnalité offre un environnement sécurisé hors ligne pour déboguer les activités d'écriture inattendues dans la base de données. Par exemple, les développeurs peuvent effectuer des requêtes telles que « récupérer tous les événements d'insertion/de mise à jour/de suppression d'e-mail pour les utilisateurs d'une équipe spécifique au cours de la semaine passée. » En utilisant également notre fonctionnalité de synchronisation à la demande, les développeurs peuvent interroger ces données dans Snowflake en quasi-temps réel. Pour respecter les politiques de rétention des données et éviter une croissance indéfinie du stockage, les données CDC sont automatiquement supprimées au bout d'une période prédéfinie.
Résultats
Ce projet a nécessité un investissement significatif en temps, en efforts et en ressources, mais le travail a porté ses fruits, avec des résultats dépassant nos attentes.
Amélioration de la fraîcheur des données
Nous avons considérablement amélioré la fraîcheur des données. Auparavant, les données avaient souvent 30 heures d'ancienneté ou plus. À présent, les données affichent trois heures d'ancienneté ou moins et les utilisateurs ont la flexibilité de configurer la fraîcheur à la minute près.
Performances évolutives
Ce pipeline gère désormais de manière fiable des tables plus de dix fois plus grandes qu'auparavant, assurant des performances constantes et prévisibles au fur et à mesure que Figma poursuit sa croissance.
Productivité des développeurs
Parce que les nouveaux outils sont toujours susceptibles de perturber les workflows, nous avons instauré une confiance avec les membres de notre équipe en les interrogeant pour identifier leurs besoins et en intégrant le pipeline aux systèmes qui leur sont familiers.
Une fois le travail achevé, nous avons pu montrer une augmentation significative de la productivité des développeurs résultant de la réduction de la surcharge opérationnelle et de l'accès quasiment en temps réel aux données en ligne au sein de l'entrepôt d'analyse.
Les développeurs peuvent désormais interroger en toute sécurité l'état actuel et l'historique des changements – à jour en quelques minutes – pour accélérer la réponse aux incidents, mieux sécuriser les déploiements et approfondir les informations.
Efficacité des coûts
Dès le début de la mise en œuvre, nous avons donné priorité à la prise en charge des bases de données partagées horizontalement. Cette prise en charge a offert un retour sur investissement fort car les bases de données partagées horizontalement comportaient moins de tables mais utilisaient plus de machines de base de données, chacune avec son propre réplica de lot. Désormais, ce pipeline génère des économies annuelles de plusieurs millions de dollars en optimisant intelligemment l'infrastructure et l'utilisation des ressources, en éliminant les traitements redondants et en évoluant de manière fluide en même temps que l'entreprise.
Opportunités futures
Notre nouvelle architecture pose les bases de plusieurs opportunités passionnantes pour améliorer et étendre encore plus le pipeline de données.
- Intégration entièrement automatisée : à l'heure actuelle, l'intégration nécessite une demande d'extraction pour ajouter des tables à une liste blanche, ce qui crée des frictions dans le processus d'intégration. Intégrer notre topologie de base de données directement au pipeline automatiserait entièrement l'intégration des tables, rationalisant l'expérience des développeurs et réduisant la surcharge manuelle.
- Prise en charge des tables à un instant donné : nous pourrions fournir la capacité d'interroger les états des tables à n'importe quel point dans le temps dans notre fenêtre de rétention CDC définie à l'aide de nos données CDC. La mise en œuvre de cette fonctionnalité améliorerait significativement les capacités de débogage, la réponse aux incidents et la flexibilité analytique.
- Modèles en aval actualisés de manière incrémentielle : une grande quantité de nos modèles analytiques en aval sont encore conçus à l'aide de processus par lots traditionnels. Notre nouveau pipeline nous permettrait d'actualiser ces modèles de manière incrémentielle, améliorant considérablement leur efficacité et réduisant la latence dans tout le workflow analytique.
Cette transformation ambitieuse a été rendue possible grâce au dévouement et aux efforts remarquables des membres actuels et passés de l'équipe d'infrastructure des données de Figma : Amadeo Casas, Alex Tian, Brandon Choi, Carter Bian, David Mah, Dorothy Chen, Ebuka Akubilo, Jimmy Xie, Krish Chainani, Merry Song, Michael Wu, Peng Wang, Raunak Agnihotri, Santosh Muthukrishnan, Xinxin Dai et Zubair Saiyed.
Nous adressons également un mot spécial de remerciement et de reconnaissance à nos équipes partenaires de soutien : Asheesh Laroia, Dylan Visher, Gordon Yoon, Gustavo Angulo Mezerhane, Langston Dziko, Ping-Min Lin, Sammy Steele, Sean Rice et Yazad Khambata.

Nous recrutons des ingénieurs ! Découvrez les conditions de travail à Figma et consultez nos postes vacants.