Prise en charge de temps de chargement de fichiers plus rapides grâce à des optimisations de mémoire en Rust




L'efficacité de la mémoire est essentielle pour une excellente expérience utilisateur. Pour des fichiers rapides, Figma recherche des optimisations ; par ex. :
Partager Prise en charge de temps de chargement de fichiers plus rapides grâce à des optimisations de mémoire en Rust
Illustration principale par Jose Flores
Le système multijoueurs de Figma gère le chargement des fichiers, la propagation des mises à jour de plusieurs collaborateurs et le stockage des instantanés standard des états de fichier. Pour rendre la collaboration en temps réel aussi rapide que possible à travers le graphe complexe d'un fichier Figma, une grande partie du fichier est chargée en mémoire.
À mesure que Figma grandit, nous cherchons des moyens de nous développer efficacement tout en préservant une excellente expérience utilisateur. En lançant le chargement dynamique des pages, nous avons constaté une augmentation de 30 % du nombre de fichiers à décoder côté serveur. Pour gérer cette nouvelle charge, nous avons étudié plusieurs optimisations de performance en Rust qui ont abouti à des temps de chargement plus rapides et à une meilleure efficacité de la mémoire.
Des cartes plus petites et économes en mémoire
Un fichier Figma est conceptuellement une collection de nœuds. Chaque nœud représente un objet différent : un triangle, un carré, une frame, etc. Et chaque nœud peut être considéré comme un ensemble de propriétés qui indiquent comment l'afficher : sa couleur, sa forme, son parent, etc.


Sur le serveur, nous représentons les nœuds sous forme de carte de clés (ID de propriété) de valeurs, ou Map<property_name (u16), property_value (u64 pointer)>, où u16 et u64 se réfèrent à la taille en bits des entrées dans la carte.
Cette carte étant sur le chemin critique de chargement d'un fichier, toute accélération ici se traduirait par des temps de chargement de fichier améliorés. De plus, grâce à un profil de la mémoire, nous avons découvert que cette carte était responsablede plus de 60 % de l'utilisation de la mémoire d'un fichier.(Étant donné que la carte ne stocke que des métadonnées et non des données, cette découverte nous a beaucoup surpris !)
Aussi, nous avons examiné cette structure de données pour essayer de l'optimiser. Nous utilisions le BTreeMap par défaut en Rust, car notre protocole de sérialisation nécessitait une itération ordonnée. Après avoir longuement réfléchi au problème, nous avons réalisé que nous n'avions pas besoin de toute la puissance d'une carte générique en raison de la plage restreinte dans laquelle nos clés résidaient.
L'espace de clé de la carte était restreint par de nouvelles propriétés ajoutées à la définition du schéma d'un fichier Figma, ce qui se produit à des vitesses humaines, c'est-à-dire extrêmement lentement. Le schéma comporte moins de 200 champs aujourd'hui, et la plupart d'entre eux apparaissent dans des grappes. Par exemple, vous ne définiriez les champs de commentaire que pour un nœud de commentaire, et non pour un autre nœud. En mesurant le nombre de champs réels dans certains fichiers d'exemple, nous avons découvert que notre hypothèse était vraie, et la taille moyenne de la carte des propriétés était d'environ 60 clés.
Forts de cette prise de conscience, nous avons décidé d'essayer une mise en page plus simple et utilisant mieux la mémoire : un vecteur plat et trié. Ainsi, notre représentation en mémoire d'un nœud est passée de :
BTreeMap<u16, pointer>{
0: 1, // node_id
1: FRAME, // type
2: null, // parent_id
... (x, y, w, h etc.)
},à :
Vec<u16, pointer>{
(0, 1),
(1, FRAME),
(2, null),
... (x, y, w, h)
}Une comparaison rapide entre les deux représentations, le style Big O, nous dit que l'approche basée sur les vecteurs est pire d'un point de vue des performances :

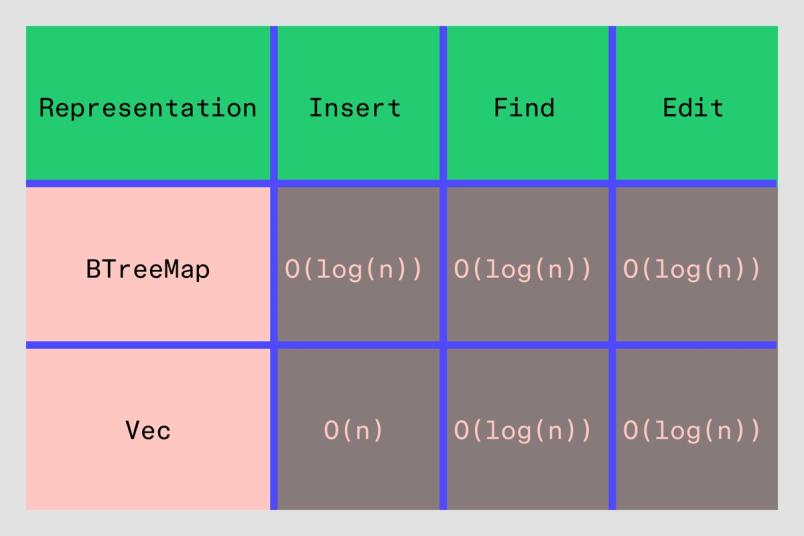
Cependant, cela ne prend pas en compte le fait que les ordinateurs sont particulièrement rapides lorsqu'ils doivent parcourir de petites quantités de mémoire linéaire et effectuer des calculs dessus (exactement le cas ici). Donc, malgré le temps d'insertion théorique O(n) (si quelque chose est inséré au début du vecteur), cette solution était plus rapide lors de la désérialisation des fichiers (ce qui est le processus le plus important pour les chargements de fichiers). Quant à notre utilisation de la mémoire, elle a chuté de près de 25 % pour les gros fichiers – un succès retentissant à grande échelle.
Économiser plus de mémoire avec le bourrage de bits
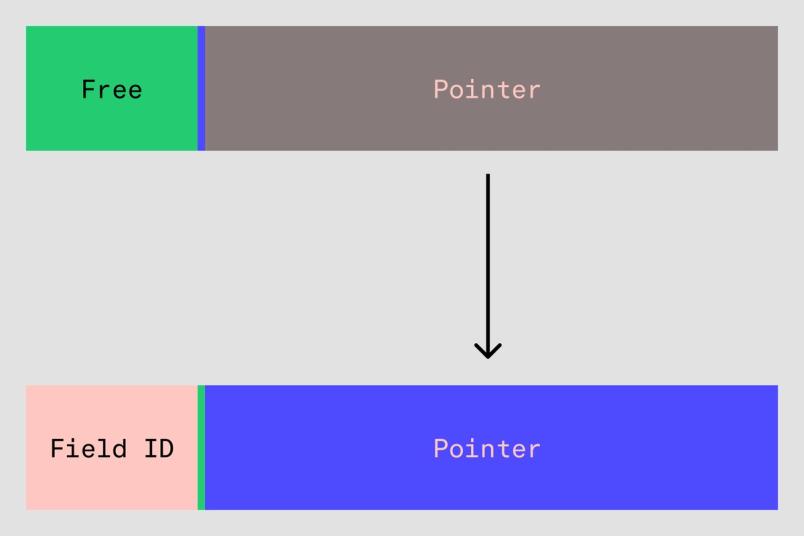
Bien que nous ayons fini par déployer la solution ci-dessus, nous avons également exploré une autre optimisation, qui n'a pas encore été mise en production. Pour comprendre, nous devons encore nous pencher sur Map<u16, pointer> et nous demander : qu'est-ce réellement qu'un pointeur ?
Un pointeur n'est que 64 bits de données qui indiquent à votre CPU local convivial où il peut trouver le début d'une autre donnée. 64 bits de données correspondent à 2^64 octets ou à 18 exaoctets de mémoire adressable – une quantité à laquelle notre système multijoueurs n'aurait jamais accès. En fait, avec la plupart des processeurs x86, vous n'avez pas besoin de tant de mémoire, et donc un pointeur sur un système x86 ressemble vraiment à ceci :
[0u16, pointer_u48]Les 48 bits inférieurs du pointeur sont la seule partie utilisée pour adresser la mémoire (bien que cela ne soit pas garanti et puisse changer à l'avenir), et les 16 bits supérieurs sont à notre disposition !
Par un heureux hasard, notre Map<u16, pointer> a exactement besoin de 16 bits supplémentaires pour stocker l'ID de champ, et nous pouvons donc remplir nos pointeurs avec l'ID de champ pour stocker à la fois l'ID de champ et le pointeur dans un seul nombre à 64 bits. Notre représentation des données ressemble maintenant à ceci :
Vec<u64>{
[0_u16 type_ptr_u48],
[1_u16, FRAME_ptr_u48],
... (x, y, w, h)
}
Nous utilisons des opérations de bots simples pour récupérer l'ID de champ et le pointeur à partir du nombre à 64 bits. L'implémentation en Rust de cette approche nous oblige à gérer avec soin le cycle de vie de ces pointeurs. Puisque nous utilisons des pointeurs comptés par référence, nous devons nous assurer que les comptes de références sont mis à jour correctement sur insert ou get pour éviter de corrompre la mémoire.
La taille de résident définie est la quantité de mémoire qu'un processus consomme dans la RAM (mémoire principale).
Cette approche s'est traduite par une performance légèrement plus rapide sur le benchmark et par une utilisation de mémoire légèrement inférieure (environ 5 % de moins que l'approche vectorielle simple). Nous nous attendions à une économie de mémoire plus importante, pensant naïvement que la nouvelle représentation devrait utiliser exactement 20 % de données en moins. Cependant, la métrique de mémoire qui nous intéresse vraiment est la taille résidente (RSS), qui ne correspond pas toujours directement à la mémoire allouée et dépend du comportement de l'allocation sous-jacente et du système d'exploitation.
Nous avons décidé de ne pas mettre en production cette optimisation pour la simple raison que le gain supplémentaire ne semblait pas valoir les risques potentiels liés à la mémoire auxquels nous nous exposions, mais il s'agit toujours d'un levier dont nous disposons désormais.
Les chiffres baissent
Utiliser un vecteur plutôt qu'une carte pour représenter les fichiers Figma en Rust a accéléré pour nos utilisateurs les temps de chargement des fichiers. Par exemple, cela a amélioré les temps de désérialisation des fichiers de 20 % au 99e percentile – les fichiers Figma les plus lents se chargent maintenant plus rapidement ! Et ce changement mineur nous a également permis d'économiser 20 % sur les coûts liés à la mémoire dans toute notre flotte multijoueurs.
Nous cherchons toujours à rendre notre technologie multijoueurs plus efficace, plus performante et plus facile à gérer grâce à des optimisations telles que celles-ci. Si cette approche vous parle, consultez nos postes vacants – nous recrutons !

Nous recrutons des ingénieurs ! Découvrez les conditions de travail à Figma et consultez nos postes vacants.