



Visibilité à grande échelle : comment Figma détecte l'exposition des données sensibles



Résoudre les problèmes de sécurité à grande échelle nécessite autant de créativité que de rigueur. Pour réduire le risque d'exposition de données sensibles, nous avons développé Response Sampling : un contrôle léger et en temps réel qui surveille les réponses sortantes, valide l'accès et offre un système d'alerte précoce sur nos produits.
Partager Visibilité à grande échelle : comment Figma détecte l'exposition des données sensibles
Illustrations par Jose Flores
Prévenir l'exposition de données sensibles de manière programmatique est l'un des défis les plus complexes de l'ingénierie de la sécurité. En raison de la nature des systèmes distribués modernes, les données peuvent parcourir des chemins complexes et parfois imprévisibles, à travers les services et les calques de sérialisation et dans des contextes où leur présence n'est pas toujours évidente. Ce type de problème peut se manifester de manière subtile : une extrémité renvoyant plus de données que prévu, un chemin de code hérité contournant une vérification de permission ou une validation manquante qui permet aux utilisateurs de voir des ressources qu'ils ne devraient pas. En termes de sécurité, il s'agit souvent de formes de failles d'autorisation ou d'une surexposition involontaire de données – des erreurs mineures qui peuvent avoir un impact considérable sur la confidentialité et la confiance à grande échelle.
Pour relever ce défi de front chez Figma, nous devions construire un système de surveillance qui agirait à la fois comme filet de sécurité et système d'alerte précoce, captant les expositions en phase de test avant qu'elles n'atteignent la production et continuant à surveiller les régressions inattendues une fois déployé. Cela signifiait construire quelque chose de suffisamment précis pour être fiable et suffisamment vaste pour être utile à travers de nombreuses parties différentes du produit.
Nous sommes ravis de partager notre expérience dans la conception de Response Sampling, un système conçu pour détecter les fuites potentielles de données sensibles en temps réel. En offrant une visibilité continue sur les données quittant nos services, Response Sampling offre à nos équipes l'opportunité d'examiner et de résoudre les problèmes rapidement, réduisant ainsi le risque d'exposition et améliorant notre confiance dans le traitement des données.
Nous avons abordé ce problème du point de vue de la sécurité de plateforme, en traitant nos surfaces d'application comme une infrastructure et en ajoutant par-dessus des contrôles de surveillance et de détection continus. En appliquant des techniques généralement réservées aux systèmes de bas niveau à notre calque applicatif, nous avons pu obtenir une visibilité continue sur la circulation des données à travers nos produits, sans ralentir le développement.
Identifier le problème : visibilité des expositions cachées
Chez Figma, nous prenons les autorisations et l'autorisation au sérieux. Au fil des ans, nous avons investi dans des contrôles préventifs performants tels quePermissionsV2, notre cadre d'autorisation granulaire, ainsi que des tests continus via des tests unitaires négatifs, des tests de bout en bout dans la préproduction et la production et des programmes d'examen de la sécurité continus (y compris notre programme de prime aux bugs et des tests de pénétration réguliers). Ces systèmes nous donnent une grande confiance dans nos limites d'accès et constituent la méthode de base par laquelle nous prévenons l'exposition de données sensibles.

En savoir plus sur la façon dont nous avons conçu PermissionsV2.
L'exposition de données sensibles est une vulnérabilité de sécurité où des informations confidentielles ou protégées sont rendues involontairement accessibles à des parties qui ne devraient pas y avoir accès, introduisant un risque d'utilisation abusive ou de perte de confiance.
Mais les mesures préventives et les tests à eux seuls ne peuvent pas détecter tous les cas particuliers. À mesure que nos produits et notre infrastructure ont gagné en complexité, le risque d’erreurs subtiles ou de flux de données inattendus a naturellement augmenté. Même les systèmes bien conçus peuvent réserver des surprises lorsque les services interagissent selon des méthodes nouvelles ou que les parcours existants ne se comportent pas comme prévu.
Étant donné l'importance de la protection des données pour Figma, nous voulions ajouter un calque de défense supplémentaire, axé sur la détection et l'observabilité. Notre objectif était de concevoir un système capable de confirmer en continu que nos contrôles préventifs fonctionnaient comme prévu et de nous aider à repérer les anomalies tôt, avant qu'elles ne puissent affecter la production.
Pour rendre cela possible, nous avions besoin d'un système pouvant :
- Surveiller en continu l'exposition potentielle, quel que soit l'endroit où elle s'est produite dans le produit.
- Fournir des informations exploitables permettant de résoudre les problèmes tôt, de préférence avant qu'ils n'affectent la production.
- Rester actif en production en tant que couche de défense supplémentaire pour détecter les régressions en temps réel.
Ces objectifs ont façonné la base de notre approche et ont orienté la manière dont nous avons équilibré l'ampleur de la détection, l'impact sur les performances et la maintenabilité opérationnelle.
Étape 1 : Concevoir Response Sampling pour les identifiants de fichier
Pour pouvoir détecter de manière programmatique l'exposition de données sensibles, nous devions d'abord décider de ce qui était considéré comme sensible. Tous les champs d'une réponse d'API ne posant pas de risque, nous avons commencé avec un type bien défini (les identifiants de fichiers) où les règles de sensibilité et d'accès étaient déjà claires. Dans Figma, les identifiants de fichiers sont les tokens uniques intégrés dans l'URL de chaque fichier et qui lient le fichier à des contrôles d'accès spécifiques. Étant des tokens de capacité à haute entropie avec un jeu de caractères connu et une longueur constante, les identifiants de fichiers sont faciles à détecter dans les flux de texte. Cela en faisait un point de départ pratique pour détecter les bugs d'autorisation et concevoir l'infrastructure qui supporterait plus tard un échantillonnage de réponse plus large des réponses une fois qu'une définition systématique des données sensibles serait disponible.

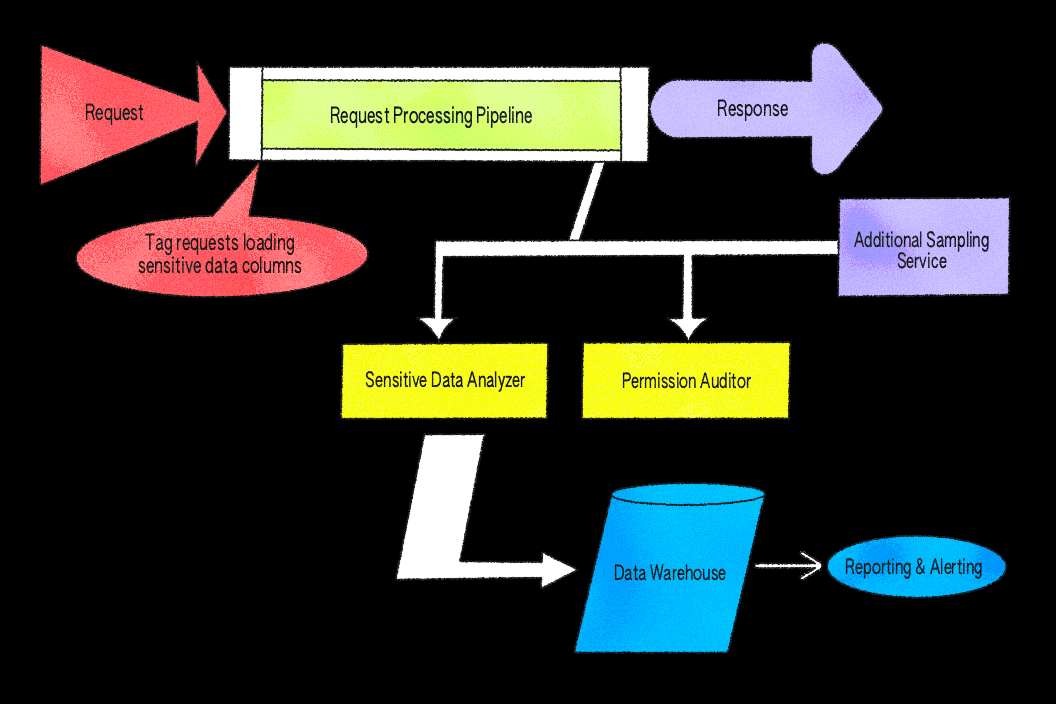
Notre mise en œuvre initiale s'est concentrée sur ce type de données et les vérifications des autorisations associées. L'idée était simple mais forte : échantillonner un petit sous-ensemble de réponses de services clés, scanner les identifiants liés aux fichiers et vérifier que l'utilisateur à l'origine de la demande est autorisé à accéder à chaque valeur. L'échantillonnage est effectué de manière uniforme et aléatoire avec un taux configurable sur les chemins de demande, ce qui nous permet de contrôler la couverture et de limiter les frais généraux tout en faisant ressortir des résultats représentatifs.
Nous avons conçu le système en tant que middleware sur notre serveur d'application Ruby car cela nous donne un accès direct à l'objet utilisateur authentifié, au corps complet de la réponse d'API et à notre système de permissions interne, PermissionsV2. Cela permet d'inspecter facilement les données de réponse et d'évaluer les permissions en un seul endroit. Nous aurions pu mettre en œuvre des vérifications similaires au niveau d'un calque proxy, tel que Envoy, mais cela aurait significativement compliqué l'évaluation des permissions sensibles au contexte utilisateur requises dans notre architecture.
Nous avons mis en œuvre l'échantillonnage de réponse à l'aide d'un bloc after et de tâches asynchrones. Le filtre after est un crochet intégré qui s'exécute automatiquement à la fin de chaque demande, nous offrant un emplacement cohérent pour inspecter les réponses avant qu'elles ne soient renvoyées au client. Le filtre inspecte les réponses éligibles selon les taux d'échantillonnage configurés et analyse les corps JSON pour extraire les identifiants de fichiers. Lorsqu'un identifiant pertinent est trouvé, le système met les travaux asynchrones en file d'attente pour vérifier les autorisations. Pour réduire les faux positifs, la logique de vérification applique des règles qui tiennent compte des cas sûrs connus, garantissant que seuls les résultats inattendus sont présentés à des fins d'examen. Tout cela ne bloque aucune opération : si l'échantillonnage ou la vérification échoue, la demande se termine normalement et les erreurs sont enregistrées à des fin de suivi.
Une extrémité interne permet à d'autres services, tels que LiveGraph, notre service de récupération de données en temps réel qui maintient les expériences de collaboration synchronisées, de soumettre leurs propres données d'échantillonnage et de réutiliser le pipeline de traitement. Après avoir produit une réponse, LiveGraph effectue un appel API léger à cette extrémité, lui permettant de bénéficier de l'échantillonnage de réponse sans ajouter de surcharge à son flux de données en temps réel. Pour maintenir des performances prévisibles, l'échantillonnage dans LiveGraph est contrôlé par une configuration et une limitation du débit. Comme les conclusions partagent le même schéma et le même chemin de journalisation que les autres services, les résultats sont unifiés dans notre entrepôt d'analyse de données et nos tableaux de bord de triage, ce qui permet aux ingénieurs de garde d'interpréter facilement les alertes, quelle qu'en soit la source.

En savoir plus sur la façon dont nous avons conçu LiveGraph.
Nous avons intégré cette logique directement dans notre infrastructure API, lui permettant de fonctionner à la fois sur le trafic de mise en scène et de production. Les taux d'échantillonnage ont été ajustés afin de capturer une couverture suffisante pour des résultats significatifs sans introduire de latence notable, et tous les contrôles ont été effectués de manière asynchrone pour ne pas ralentir le cycle de demande-réponse. De plus, une limitation de taux a été mise en place pour éviter que le pipeline de traitement ne soit surchargé et éviter une consommation excessive des ressources.
Cette approche a immédiatement révélé des informations précieuses. Dans les jours suivant le déploiement, Response Sampling a mis en lumière des cas subtils où des identifiants liés aux fichiers étaient inutilement renvoyés dans certaines réponses, incitant à un meilleur filtrage des données. L'application a également révélé des chemins où certains fichiers contournaient entièrement les vérifications de permission, ce qui nous a permis de combler ces lacunes et de renforcer nos contrôles d'accès globaux.
La première étape a prouvé le concept, mais sa portée était limitée. Les identifiants de fichiers sont importants, mais ils ne représentent qu'une catégorie d'informations sensibles que nous devons protéger.
Étape 2 : Augmenter la visibilité avec un échantillonnage de réponse élargi
Une fois les bases établies, nous nous sommes mis à élargir la portée du système. La mise en œuvre initiale a prouvé que l'échantillonnage de réponse pouvait détecter efficacement de réels problèmes d'autorisation, mais elle était limitée à un seul type de données. Le défi suivant a consisté à faire évoluer la même approche à n'importe quel champ sensible – essentiellement, apprendre au système ce que signifie « sensible » dans nos produits.
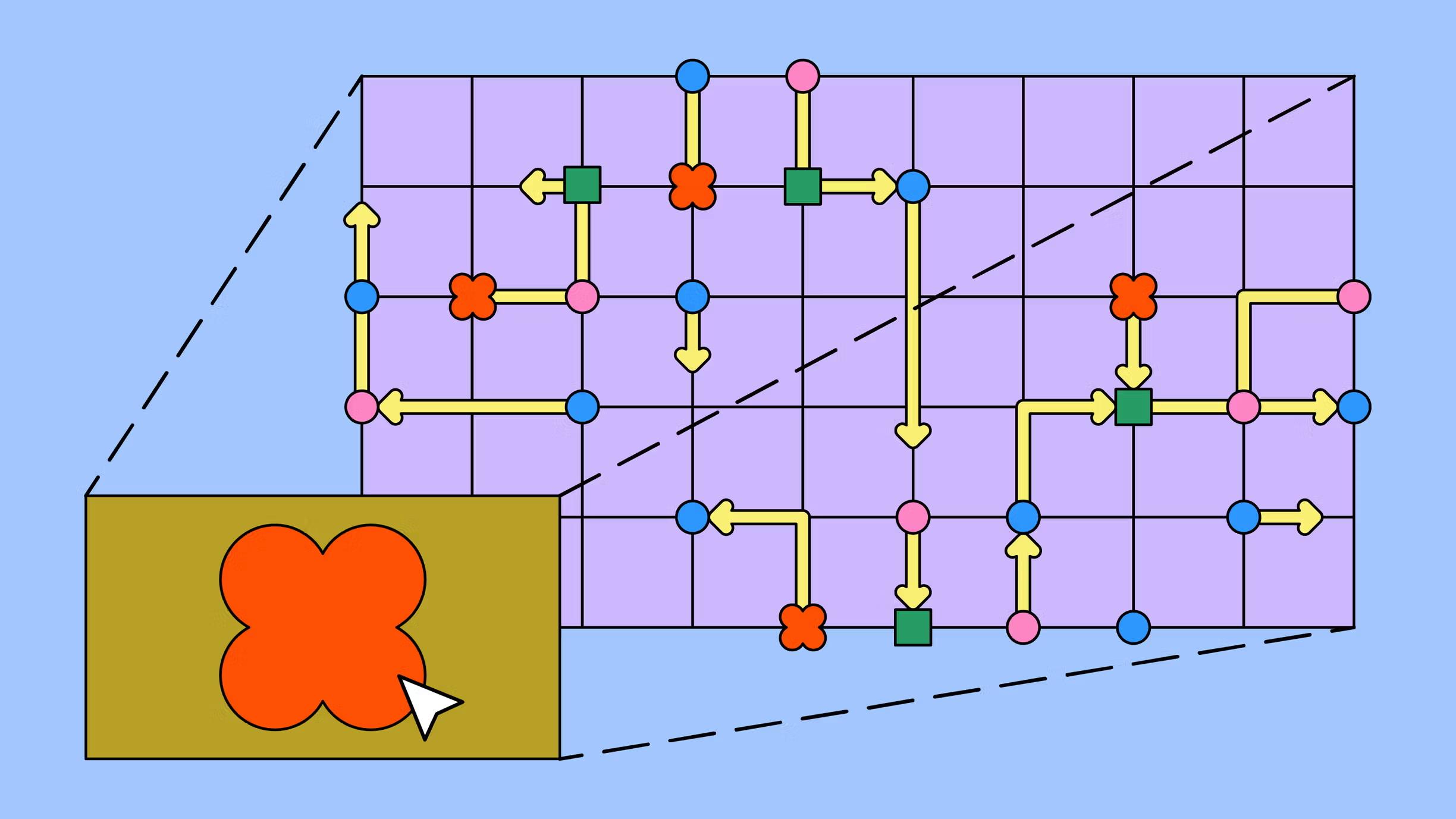
L'échantillonnage de réponse étendu, affectueusement appelé « échantillonnage de réponse sophistiqué » en interne, a étendu les mêmes principes d'échantillonnage à toutes les données sensibles en s'intégrant à FigTag, notre outil interne de catégorisation des données.

FigTag fonctionne en annotant chaque colonne de base de données avec une catégorie qui décrit sa sensibilité et son utilisation prévue. Ces annotations sont stockées dans un schéma central et propagées à notre entrepôt de données, ce qui permet de déterminer facilement la sensibilité d'une colonne au moment de la requête. L'une de ces catégories, banned_from_clients, agit comme signal de la sensibilité, indiquant les champs qui ne doivent pas être retournés dans les réponses d'API dans des circonstances normales (par exemple, les identifiants liés à la sécurité, les détails de facturation et d'autres informations personnelles identifiables).
Grâce à l'intégration de FigTag, nous sommes capables d'échantillonner un sous-ensemble de réponses contenant n'importe quel champ sensible, sur toutes nos extrémités d'API de serveur d'application. Lorsqu'un enregistrement de base de données comportant une colonne banned_from_clients est chargé dans l'application (dans notre cas, via un modèle ActiveRecord, le calque de mapping relationnel-objet utilisé dans notre application Ruby), un rappel enregistre sa valeur dans un stockage local à la demande. Pour les demandes échantillonnées, cela garantit que seules les valeurs effectivement consultées pendant la requête sont suivies, ce qui permet d'éviter des frais généraux inutiles.
Une fois la réponse générée, un filtre after inspecte le JSON sérialisé et le compare aux valeurs sensibles enregistrées. Si des valeurs sensibles apparaissent dans la réponse, un journal est enregistré. Comme auparavant, les résultats arrivent à notre entrepôt d'analyse unifiée et à nos tableaux de bord.
Nous avons également introduit un processus de mise en liste blanche flexible, de sorte que les extrémités présentant une exposition intentionnelle et sûre peuvent être exclues de l'échantillonnage de réponse sans sacrifier la détection de données réellement inattendues. Par exemple, un secret client OAuth pourrait être intentionnellement renvoyé à partir d'une extrémité dédiée de gestion des informations d'identification pour les utilisateurs autorisés, mais cela poserait un sérieux problème s'il était inclus dans des réponses d'API non liées.
Détection précoce en action
Le système d'échantillonnage de réponse étendu est aujourd'hui un calque de détection puissant, mettant en évidence des problèmes subtils qui auraient été extrêmement difficiles à détecter dans le cadre d'une révision de code ou d'un contrôle qualité manuel simple. Il nous a permis de repérer de manière proactive les risques en préproduction et de réagir rapidement aux régressions de production. Voici quelques exemples :
- Nous avons découvert qu'un champ de données longtemps inutilisé s'introduisait de manière inattendue dans certaines réponses. L'équipe a confirmé la découverte, l'a catégorisée et a rapidement envoyé une correction ciblée.
- Le système a mis en évidence des cas où des données de ressources liées étaient incluses dans les réponses sans un besoin clair, ce qui a conduit à un travail de nettoyage ciblé.
- L'échantillonnage de réponse a mis en évidence des scénarios où nous retournions une liste de ressources dans une réponse sans vérifier l'accès pour chaque élément individuellement, incitant à améliorer les vérifications de permission.
Leçons apprises de l'équilibre entre précision et performances
Concevoir des systèmes comme celui-ci est un effort inter-équipes chez Figma. Nos ingénieurs en sécurité expédient du code aux côtés des équipes produit et plateforme, apportant aux systèmes de détection la créativité et la rigueur que nous apportons aux fonctionnalités orientées utilisateur.
Après des mois de développement et d'exécution de Response Sampling, nous avons beaucoup appris sur ce qu'il faut faire pour concevoir un système de détection programmatique :
- Toujours penser à l'impact sur les performances : nous avons constaté que même une surveillance limitée peut introduire une latence si elle n'est pas conçue avec soin. En ajustant les taux d'échantillonnage et en exécutant les contrôles de manière asynchrone, nous avons maintenu des performances visibles par l'utilisateur tout en obtenant une visibilité significative sur le trafic.
- Gérer les faux positifs (ou ils vous géreront !) : Un taux élevé de faux positifs peut accabler les équipes et réduire la confiance dans les alertes. Pour y remédier, nous avons mis en œuvre des listes d'autorisation dynamiques et des workflows de tri rigoureux. Cela a impliqué de filtrer rapidement les cas connus comme sûrs et a permis aux ingénieurs de se concentrer sur les découvertes vraiment risquées.
- Le contexte compte : toutes les expositions de données sensibles ne sont pas également problématiques. En utilisant une configuration dynamique, nous avons pu rapidement ajuster les règles de détection sans redéployer les services. Cela a permis une gestion nuancée des cas d'utilisation légitimes tout en signalant les scénarios anormaux ou inattendus.
- Créer une défense en couches : exécuter le système à la fois en préproduction et en production nous a apporté deux lignes de défense : une détection précoce avant la mise en production et une surveillance continue pour détecter les régressions. Cette approche de défense en profondeur a été essentielle pour maintenir une résilience à long terme.

La voie à suivre
Avec l'échantillonnage de réponse, nous avons appliqué une approche de sécurité de la plateforme à la sécurité des produits – en superposant une surveillance et une détection continues à nos surfaces d'application pour détecter les problèmes tôt sans ralentir le développement.
Nous élargissons ce cadre pour couvrir davantage de services et d'autres points de contact avec l'utilisateur afin de pouvoir identifier les risques potentiels sur tous les canaux d'interaction principaux. Nous prévoyons également d'étendre la couverture à d'autres catégories de données sensibles, y compris des classes plus larges de PII et de données réglementées, garantissant que nos capacités de détection évoluent avec les besoins de conformité.
Pour maintenir l'efficacité de l'échantillonnage de réponse à mesure que nos systèmes se développent, nous explorons des moyens de le rendre plus adaptatif et instructif. Par exemple, nous examinons des contrôles d'échantillonnage plus précis pour équilibrer l'utilisation des ressources avec la visibilité, ainsi qu'une hiérarchisation automatique pour accélérer les investigations et des rapports plus riches pour mettre en évidence les tendances au fil du temps. À mesure que nous développons ce cadre, notre objectif reste le même : protéger les données des utilisateurs et garantir que chaque expérience Figma demeure rapide, fiable et sécurisée.
Les équipes AppSec utilisent rarement les approches de sécurité des infrastructures, mais la création d'un système d'échantillonnage de réponse a montré à quel point ces approches peuvent être efficaces lorsqu'elles sont appliquées au calque de l'application. Rapprocher la détection continue du calque de l'application nous a aidés à identifier les problèmes plus tôt et à réagir plus rapidement – une approche qui selon nous pourrait bénéficier à d'autres équipes.

Nous recrutons des ingénieurs ! Découvrez les conditions de travail à Figma et consultez nos postes ouverts.



