Visibilidade em escala: Como o Figma detecta exposição de dados sensíveis



Resolver desafios de segurança em escala requer tanta criatividade quanto rigor. Para reduzir o risco de exposição de dados sensíveis, desenvolvemos o Response Sampling: um controle leve e em tempo real que monitora respostas de saída, valida o acesso e fornece um sistema de alerta precoce em nossos produtos.
Compartilhar Visibilidade em escala: Como o Figma detecta exposição de dados sensíveis
Ilustrações por Jose Flores
Prevenir a exposição de dados sensíveis programaticamente é um dos desafios mais complexos na engenharia de segurança. A natureza dos sistemas modernos e distribuídos significa que os dados podem percorrer caminhos intricados e às vezes imprevisíveis—através de serviços, por camadas de serialização, e em contextos onde sua presença nem sempre é óbvia. Esses tipos de problemas podem se manifestar de maneiras sutis: uma extremidade retornando mais dados do que o pretendido, um caminho de código legado pulando uma verificação de permissão, ou uma validação ausente que permite que os usuários vejam recursos que não deveriam. Em termos de segurança, frequentemente são falhas de autorização ou exposição acidental de dados—pequenos erros que podem ter impactos desproporcionais na privacidade e confiança em larga escala.
Para enfrentar este desafio de frente na Figma, precisávamos construir um sistema de monitoramento que atuasse como uma rede de segurança e um sistema de alerta precoce, detectando exposições na fase de teste antes de chegarem à produção, e continuando a monitorar regressões inesperadas uma vez implantadas. Isso significava construir algo preciso o suficiente para ser confiável e amplo o suficiente para ser valioso em várias partes diferentes do produto.
Estamos animados para compartilhar nossa experiência construindo o Response Sampling, um sistema projetado para detectar possíveis vazamentos de dados sensíveis em tempo real. Ao fornecer visibilidade contínua sobre os dados que saem de nossos serviços, o Response Sampling oferece às nossas equipes a oportunidade de investigar e resolver problemas rapidamente, reduzindo o risco de exposição e aumentando nossa confiança em como os dados são tratados.
Abordamos esse problema com uma mentalidade de segurança de plataforma — tratando as superfícies do nosso aplicativo como infraestrutura e adicionando monitoramento contínuo e controles de detecção no topo. Ao aplicar técnicas geralmente reservadas para sistemas de baixo nível à nossa camada de aplicação, conseguimos obter visibilidade contínua sobre como os dados transitam por nossos produtos, sem atrasar o desenvolvimento.
Identificando o problema: Visibilidade em exposições ocultas
Na Figma, levamos a sério as permissões e autorizações. Ao longo dos anos, investimos em controles preventivos robustos, como o PermissionsV2, nosso framework de autorização detalhado, bem como em testes contínuos através de testes de unidade negativos, testes de ponta a ponta em fase de staging e produção, e programas contínuos de revisão de segurança (incluindo nosso programa de recompensas por bugs e testes regulares de penetração). Esses sistemas nos dão uma forte confiança em nossos limites de acesso e formam a base de como prevenimos a exposição de dados sensíveis.

Leia mais sobre como construímos o PermissionsV2.
A exposição de dados sensíveis é uma vulnerabilidade de segurança onde informações confidenciais ou protegidas são acessadas acidentalmente por partes que não deveriam ter acesso, criando risco de uso indevido ou perda de confiança.
Mas medidas preventivas e testes por si só não podem capturar todos os casos de edge. À medida que nossos produtos e infraestrutura cresceram em complexidade, o risco de pequenas negligências ou fluxos de dados inesperados aumentou naturalmente. Mesmo sistemas bem projetados podem produzir surpresas quando os serviços interagem de novas maneiras ou quando caminhos existentes se comportam de forma diferente do esperado.
Dado o quão importante é a proteção de dados para a Figma, queríamos adicionar outra camada de defesa, uma focada em detecção e observabilidade. Nosso objetivo era construir um sistema que pudesse validar continuamente se nossos controles preventivos estavam funcionando conforme o planejado e nos ajudar a identificar anomalias cedo, antes que pudessem afetar a produção.
Para fazer isso possível, precisávamos de um sistema que pudesse:
- Monitorar continuamente a exposição potencial, independentemente de onde ela ocorreu no produto.
- Fornecer insights acionáveis que nos permitam resolver problemas antecipadamente, idealmente antes de atingirem a produção.
- Permanecer ativo em produção como uma camada adicional de defesa para detectar regressões em tempo real.
Esses objetivos moldaram a base da nossa abordagem e guiaram como equilibramos a amplitude de detecção, o impacto no desempenho e a manutenibilidade operacional.
Passo 1: Construindo Amostragem de Resposta para identificadores de arquivo
Antes de podermos detectar a exposição de dados sensíveis programaticamente, primeiro tivemos que decidir o que contava como sensível. Nem todos os campos em uma resposta de API representam um risco, então começamos com um tipo bem definido—identificadores de arquivo—onde as regras de sensibilidade e acesso já estavam claras. Os identificadores de arquivos no Figma são os tokens únicos embutidos na URL de cada arquivo que os vinculam a controles de acesso específicos. Como são tokens de capacidade de alta entropia com um conjunto de caracteres conhecido e comprimento consistente, identificadores de arquivo são fáceis de detectar em fluxos de texto. Isso os tornou um ponto de partida prático para detectar bugs de autorização e para construir a infraestrutura que mais tarde apoiaria uma amostragem de resposta mais ampla, uma vez que uma definição sistemática de dados sensíveis estivesse disponível.

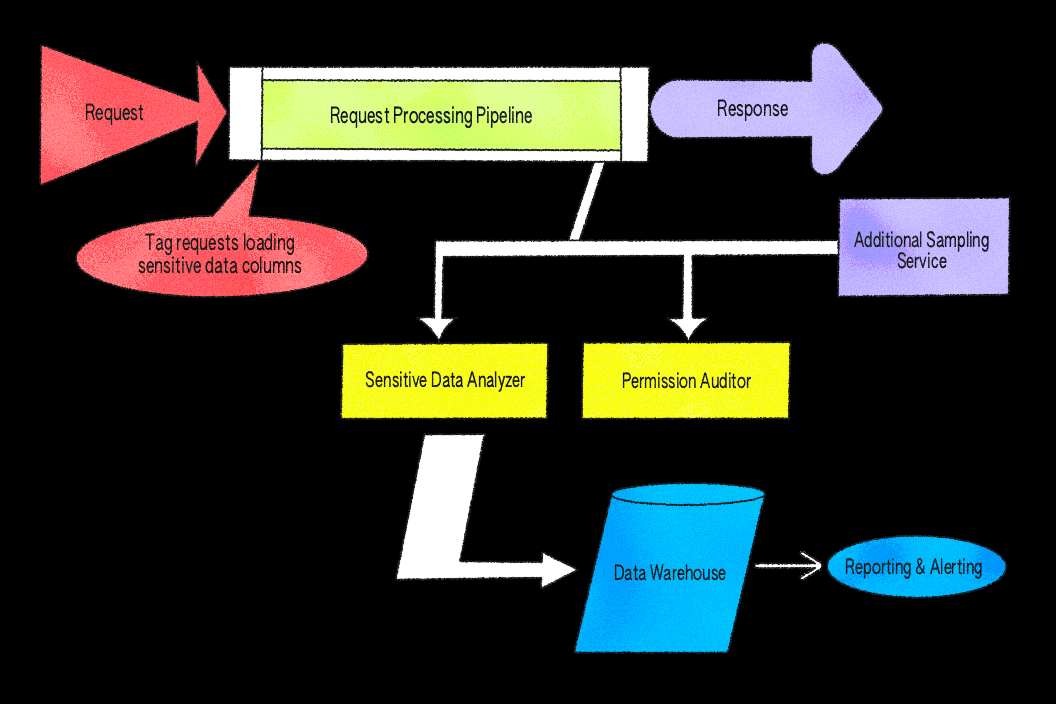
Nossa implementação inicial focou nesse tipo de dado e nas verificações de permissão associadas a ele. A ideia era simples, mas poderosa: Amostrar um pequeno subconjunto de respostas de serviços-chave, procurar identificadores vinculados a arquivos e verificar se o usuário da solicitação tinha permissão para acessar cada valor. A amostragem é realizada uniformemente ao acaso com uma taxa configurável nos caminhos de solicitação, permitindo-nos controlar a cobertura e limitar a sobrecarga enquanto ainda apresentamos resultados representativos.
Construímos o sistema como middleware em nosso servidor de aplicações Ruby porque ele fornece acesso direto ao objeto de usuário autenticado, ao corpo completo da resposta da API e ao nosso sistema interno de permissões, PermissionsV2. Isso torna simples inspecionar dados de resposta e avaliar permissões em um único lugar. Enquanto poderíamos ter implementado verificações semelhantes em uma camada de proxy, como Envoy, isso tornaria significativamente mais difícil realizar as avaliações de permissões cientes do contexto do usuário, necessárias em nossa arquitetura.
Implementamos a Amostragem de Resposta utilizando um bloco after e tarefas assíncronas. O filtro after é um gancho embutido que é executado automaticamente após cada solicitação ser concluída, fornecendo um ponto consistente para inspecionar as respostas antes de serem enviadas de volta ao cliente. O filtro inspeciona respostas elegíveis de acordo com taxas de amostragem configuradas e analisa corpos JSON para extrair identificadores de arquivos. Quando um identificador relevante é encontrado, o sistema coloca em fila tarefas assíncronas para verificar permissões. Para reduzir falsos positivos, a lógica de verificação aplica regras que levam em consideração casos conhecidos seguros, assegurando que apenas resultados inesperados sejam apresentados para revisão. Tudo isso é não bloqueante — se a amostragem ou a verificação falhar, a solicitação ainda é concluída normalmente, e erros são registrados para monitoramento.
Uma extremidade interna permite que outros serviços, como o LiveGraph, nosso serviço de busca de dados em tempo real que mantém as experiências de colaboração sincronizadas, enviem seus próprios dados de amostragem e reutilizem o pipeline de processamento. Depois de produzir uma resposta, o LiveGraph faz uma chamada de API leve para essa extremidade, permitindo que ele se beneficie da Amostragem de Respostas sem adicionar sobrecarga ao seu fluxo de dados em tempo real. Para manter o desempenho previsível, a amostragem no LiveGraph é controlada por configuração e limite de taxa. As descobertas compartilham o mesmo esquema e caminho de registro que outros serviços, portanto, os resultados são unificados em nosso armazém de análises e painéis de triagem, facilitando para os engenheiros de plantão interpretarem alertas, independentemente de sua fonte.

Leia mais sobre como construímos o LiveGraph.
Incorporamos essa lógica diretamente em nossa infraestrutura de API, permitindo que ela funcione tanto no tráfego de staging quanto no de produção. As taxas de amostragem foram ajustadas para capturar cobertura suficiente para resultados significativos sem introduzir latência perceptível, e todas as verificações foram realizadas de forma assíncrona para evitar a desaceleração do ciclo de solicitação-resposta. Além disso, o limite de taxa foi implementado para evitar que o pipeline de processamento ficasse sobrecarregado e para evitar o consumo excessivo de recursos.
Essa abordagem começou imediatamente a revelar insights valiosos. Dentro de poucos dias após o lançamento, a Amostragem de Respostas destacou casos sutis onde identificadores relacionados a arquivos eram retornados desnecessariamente em certas respostas, o que levou a um melhor filtro de dados. Isso também revelou caminhos em que certos arquivos ignoravam completamente as verificações de permissão, permitindo-nos fechar essas lacunas e fortalecer nossos controles gerais de acesso.
O primeiro passo provou o conceito, mas seu escopo era limitado. Identificadores de arquivos são importantes, mas representam apenas uma categoria de informações sensíveis que precisamos proteger.
Etapa 2: Aumentando a visibilidade com Amostragem de Resposta expandida
Com a fundação no lugar, nos propusemos a ampliar o alcance do sistema. A implementação inicial provou que a Amostragem de Respostas poderia detectar problemas reais de autorização de forma eficiente, mas estava limitada a um único tipo de dado. O próximo desafio era expandir o mesmo método para qualquer campo sensível – essencialmente, ensinar o sistema a reconhecer o que significa “sensível” em nossos produtos.
A Expansão do Amostrador de Resposta, carinhosamente chamada de “Amostrador de Resposta Elegante” internamente, estendeu os mesmos princípios de amostragem a todos os dados sensíveis, integrando-se com o FigTag, nossa ferramenta interna de categorização de dados.

O FigTag funciona anotando cada coluna do banco de dados com uma categoria que descreve sua sensibilidade e uso pretendido. Essas anotações são armazenadas em um esquema central e propagadas para nosso data warehouse, facilitando a determinação da sensibilidade de uma coluna no momento da consulta. Uma dessas categorias, banned_from_clients, atua como nosso sinal de sensibilidade, marcando campos que não devem ser retornados em respostas de API em circunstâncias normais (por exemplo, identificadores relacionados à segurança, detalhes de cobrança e outras PII).
Ao integrar com o FigTag, conseguimos amostrar um subconjunto de respostas que contêm qualquer campo sensível, em todos os nossos pontos de extremidade da API do servidor de aplicações. Quando um registro de banco de dados com uma coluna marcada como proibida para clientes é carregado na aplicação (no nosso caso, através de um modelo ActiveRecord, a camada de mapeamento objeto-relacional usada em nossa aplicação Ruby), um callback registra seu valor no armazenamento local de solicitação. Para solicitações amostradas, isso garante que apenas os valores realmente acessados durante a solicitação sejam rastreados, evitando sobrecarga desnecessária.
Uma vez gerada a resposta, um filtro after inspeciona o JSON serializado e o compara com os valores confidenciais registrados. Se algum valor confidencial aparecer na resposta, um registro é gerado. Como antes, os resultados são direcionados para nosso armazém unificado de análises e painéis de controle.
Também introduzimos um processo flexível de lista de permissões, para que extremidades com exposição intencional e segura possam ser excluídas da Amostragem de Resposta sem sacrificar a detecção de dados verdadeiramente inesperados. Por exemplo, um secreto de cliente OAuth pode ser intencionalmente retornado de uma extremidade de gerenciamento de credenciais dedicada para usuários autorizados, mas seria um problema grave se incluído em respostas de API não relacionadas.
Detecção precoce em ação
O sistema de Amostragem de Resposta expandida tornou-se uma poderosa camada de detecção, revelando questões sutis que seriam extremamente difíceis de detectar apenas por revisão de código ou QA manual. Isso nos permitiu identificar proativamente riscos em ambientes de teste e responder rapidamente a regressões em produção. Aqui estão alguns exemplos:
- Detectamos um campo de dados há muito não usado inesperadamente fazendo seu caminho em certas respostas. A equipe confirmou a descoberta, categorizou-a e rapidamente enviou uma correção direcionada.
- O sistema trouxe à tona casos em que dados de recursos relacionados foram incluídos em respostas sem uma necessidade clara, levando a um trabalho de limpeza direcionado.
- A Amostra de Respostas destacou cenários onde estávamos retornando uma lista de recursos em uma resposta sem verificar acesso para cada item individualmente, exigindo melhorias nas verificações de permissão.
Lições aprendidas para equilibrar precisão e desempenho
Construir sistemas como este é um esforço entre equipes na Figma. Nossos engenheiros de segurança enviam código junto com as equipes de produto e plataforma, trazendo a mesma criatividade e rigor para sistemas de detecção que fazemos para recursos voltados ao usuário.
Após meses construindo e executando o Response Sampling, aprendemos muito sobre o que é necessário para construir um sistema de detecção programática:
- Sempre pense no impacto no desempenho: Descobrimos que mesmo pequenas quantidades de monitoramento podem introduzir latência se não forem projetadas cuidadosamente. Ao ajustar as taxas de amostragem e executar verificações de forma assíncrona, mantivemos o desempenho voltado para o usuário enquanto ainda obtínhamos uma visibilidade significativa do tráfego.
- Gerencie falsos positivos (ou eles gerenciarão você!): Uma alta taxa de falsos positivos pode sobrecarregar as equipes e reduzir a confiança nos alertas. Para resolver isso, implementamos listas de permissão dinâmicas e fluxos de trabalho de triagem rigorosos. Isso significou filtrar rapidamente os casos conhecidos como seguros e permitir que os engenheiros se concentrem em descobertas genuinamente arriscadas.
- O contexto importa: Nem todas as exposições de dados sensíveis são igualmente problemáticas. Ao usar uma configuração dinâmica, pudemos ajustar rapidamente as regras de detecção sem relançar os serviços. Isso permitiu um tratamento sutil dos casos de uso legítimos, ainda sinalizando cenários anormais ou inesperados.
- Crie uma defesa em camadas: Executar o sistema tanto em estágio quanto em produção nos deu duas linhas de defesa: detecção precoce antes do lançamento e monitoramento contínuo para detectar regressões. Essa abordagem de defesa em profundidade tem sido crítica para manter a resiliência a longo prazo.

O caminho a seguir
Com a Amostragem de Resposta, aplicamos uma abordagem de segurança de plataforma à segurança do produto—adicionando monitoramento contínuo e detecção em cima de nossas superfícies de aplicação para detectar problemas precocemente sem desacelerar o desenvolvimento.
Estamos expandindo essa estrutura para cobrir mais serviços e outros pontos de contato voltados para o usuário, para que possamos identificar possíveis exposições em todos os principais canais de interação. Também planejamos estender a cobertura a categorias adicionais de dados sensíveis, incluindo classes mais amplas de PII e dados regulamentados, garantindo que nossas capacidades de detecção acompanhem as necessidades de conformidade em evolução.
Para manter a Amostragem de Resposta eficaz à medida que nossos sistemas crescem, estamos explorando formas de torná-la mais adaptável e perspicaz. Por exemplo, estamos investigando controles de amostragem mais detalhados para equilibrar o uso de recursos com visibilidade, triagem automatizada para acelerar investigações e relatórios mais ricos para revelar tendências ao longo do tempo. À medida que expandimos essa estrutura, nosso objetivo permanece o mesmo: proteger os dados dos usuários e garantir que toda experiência com a Figma continue rápida, confiável e segura.
As equipes de AppSec não costumam adotar abordagens de segurança de infraestrutura, mas construir o Response Sampling mostrou como podem ser eficazes quando aplicadas na camada de aplicação. Trazer a detecção contínua mais próxima da camada de aplicação nos ajudou a encontrar problemas mais cedo e responder mais rápido—uma abordagem que achamos que outras equipes poderiam adotar.

Estamos contratando engenheiros! Saiba mais sobre a vida na Figma e veja nossas vagas abertas.