Making multiplayer more reliable


Design has always been a team sport. These improvements make sure everyone is on the same page.
Share Making multiplayer more reliable
Being browser-first is more than a feature, it's a responsibility. Our platform team spends a lot of time focusing on how to make Figma just work for the people that depend on it.
Over the last year, we’ve created a write-ahead log that makes our system more reliable than before. 95% of edits to a Figma file get saved within 600ms, which means that as the teams that use Figma scale, their work can scale with them. We wanted to share exactly how we got to that sort of reliability, but before we get started, we’ll need to provide some context on how exactly Figma’s multiplayer editing works.
How multiplayer works
Real-time multiplayer editing and collaboration is one of Figma’s key features, and we’ve written about how it works on the blog before. In this post, we’ll dive into what multiplayer infrastructure looked like before we added the write-ahead log and underscore the changes we’ve made since then.
When you open a Figma file in your browser, the client establishes a websocket connection to our servers—a service we call multiplayer. This service synchronizes the state of the file across multiple clients by receiving and broadcasting updates to all connected clients. Multiplayer is authoritative and handles validation, ordering, and conflict resolution. In order to keep things as fast as possible, multiplayer holds the state of the file in-memory and updates it as changes come in.
Because keeping state in-memory is volatile, multiplayer periodically writes the state of the file to storage every 30 to 60 seconds in a process we call “checkpointing.” To create a checkpoint, the entire file is encoded into a binary format, compressed, and uploaded to S3. This system is simple, easy to understand, and is fundamental to how some of our product features work.

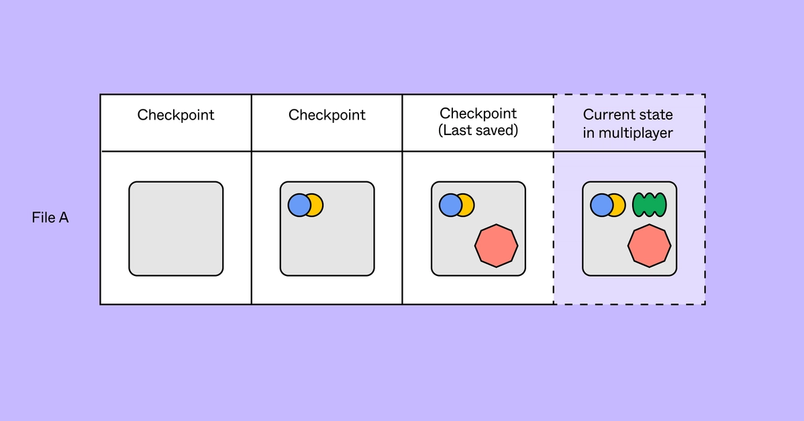
But a checkpoint-centric system has a number of downsides. Since checkpoints were created only every ~60 seconds, we could lose up to 60 seconds of work on the server-side if multiplayer crashes. And while the probability of failure in this system is low, we want to continue improving our reliability so that even when issues happen they’re completely transparent to the user.
We wanted to reduce our reliance on checkpoints for internal reasons as well. A checkpoint-centric system causes large spikes in checkpoint load when multiplayer is re-deployed. Before a file can be closed, it first needs to ensure that all changes are saved to a checkpoint. During normal operation, files are opened and closed at a regular rate, checkpoints are made periodically, and the rate of checkpoints across all files averages out to a steady rate. However, when multiplayer is re-deployed, all files that are held in memory are closed, which causes a surge in checkpoints and subsequently increased load on the database.
Introducing the journal
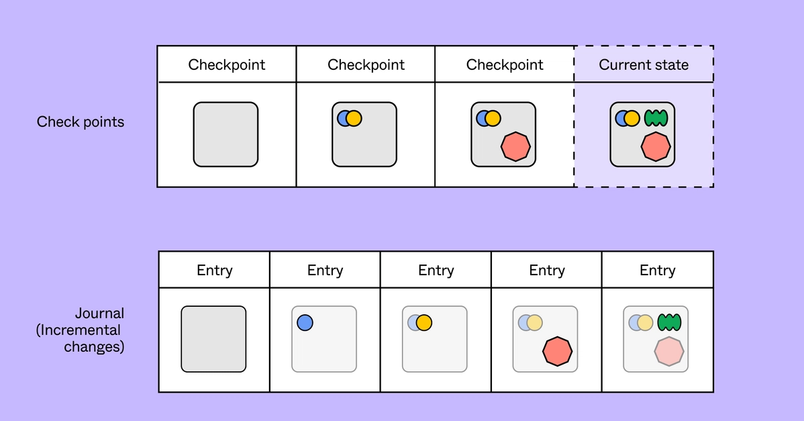
In order to address those issues and improve the state of the system, we decided to add a transaction log. The transaction log acts as a journal of changes made to the file, and it is core to our approach. At a high level, the journal is a durable datastore that is asynchronously written to as multiplayer accepts incoming changes. Each change is assigned a sequence number, which is an incrementing integer associated with the file. Every checkpoint is written with the current sequence number as well.
Here’s how that works in practice:
Let's say multiplayer crashes. On next load, the latest checkpoint is read as usual, and is 60 seconds out of date. But after the checkpoint is loaded, multiplayer queries for all entries that are newer (i.e. have a higher sequence number) than the checkpoint. With these entries, multiplayer is able to recover to the latest state of the file. As long as data is written to the journal quickly, data loss in rare failure conditions stays minimal. (Our goal was <1s of data loss.)
The journal is helpful because we’re simply writing data more frequently (think: every 0.5 seconds vs. every 60 seconds). But there’s a big distinction between the data that we’re writing to the journal vs. in a checkpoint. The entries in the journal are the incremental changes that users are making to the file, like an editor tweaking copy or a designer updating a mockup. Writing a checkpoint scales based on the size and complexity of the entire file, which accumulate over time as companies and users build more complex files and design systems. The contents of an entire file are often orders of magnitude larger than the incremental updates to the file. Journal entries and checkpoints are dual solutions that make the entire platform more reliable, whether you’re shifting a couple pixels or starting from scratch.

Another benefit of the journal is that we also solved our spike in writes (i.e. checkpoints) during deployment. Because we’re able to write changes more frequently, all we have to do when deploying multiplayer is to close all connections and wait for any unsaved changes to be persisted in the journal. (For the 99th percentile this takes less than 1 second.) Because this is now just normal behavior for the platform, the write-load on the journal stays steady and predictable and we don’t cause any extra load on the database.
Making a more perfect journal
At a high-level the concept of a journal is simple, but there were a number of tricky details that we had to make sure we got right. Here are some other details about our efforts to improve multiplayer reliability:
Datastore considerations
We used DynamoDB as our backing datastore, but considered a number of other options ranging from databases we were more familiar with, to writing to attached local volumes. For example, we also use Postgres heavily in our architecture, but chose not to use it here because we understood that the volume of writes would require us to consider a horizontally-scalable database—and we’re not there quite yet with Postgres.
Changes, batched
Because clients send updates every 33ms (30 FPS) and we don’t need that level of granularity in the journal, we can improve performance by batching multiple changes together and only writing to the journal every so often. This requires that our data-model for journal entries needs to change to have a start_sequence_number and end_sequence_number. This is harder to reason about, for example, if we load a checkpoint with sequence number 7, the journal might have an entry with sequence numbers [start: 5, end: 9]. But this still works for our use case because applying that entry will still result in the correct file at sequence number 9 due to the last-writer wins conflict resolution strategy we use.
Managing conflicting writes
Remember how multiplayer keeps the state of the file in-memory? It’s important that all clients that open a particular file get connected to the multiplayer instance that has the file open; otherwise we’d get into “split brain” and clients on one instance would see something different than clients on another instance. With the addition of the journal, the failure cases get even more complex because contending multiplayer instances could write conflicting histories in the journal and corrupt it.
To solve this, we added a mechanism to lock the file via a new table in DynamoDB. Multiplayer writes a (lock UUID, file key) entry to take ownership of that file. When new entries are being written to the journal, the update is conditional on the lock UUID matching in the other table. Finally, we ensure that entries from the journal are not read until after ownership is acquired, and the reads are strongly consistent. These changes ensure that only one Multiplayer instance is writing to the journal at a time and that the handoff handles race-conditions.
An alternative to cross-region replication
To ensure that we can recover from the most extreme scenarios, we want file data to be cross-region replicated within 30 minutes.
Unfortunately, existing solutions for cross-region replication with DynamoDB did not work for our needs. One approach is to use global tables, however the cost of replicated writes was too much—and discussion with AWS confirmed that it was not the ideal or intended usage of global tables. Our estimates showed that this would increase the cost of the feature by 6x! Another solution is to schedule regular backups of the table and export them to S3, where they can easily be replicated across regions. Unfortunately, creating a backup with the write-load and table size we had would take longer than 30 minutes. The ideal solution would be to use point-in-time (incremental) backups that were cross-region replicated, but that wasn’t supported at the time.
So file data in the journal isn’t cross-region replicated. But because checkpoints are stored in S3 and already set up to be replicated cross-region, we found that we were able to satisfy the 30-minute goal by ensuring that all changes in the journal were checkpointed within that time frame. For cases where multiplayer closes the file without checkpointing, it also enqueues an async job which will trigger a checkpoint after some jittered delay. The delay is important because we don’t want to re-introduce a spike of writes when multiplayer is re-deployed.
Journal consistency
How do we make sure that the journal is capturing writes to the file from all code paths? We don’t want to lose any data when we read the state from the journal instead of a checkpoint. And because writes depend on the context of the file when they were written, applying without the correct context could cause unexpected behavior. For example, if update A moves a child node out from a parent node, and update B deletes the parent node, applying update B without update A would result in the child node being deleted unexpectedly.
This is where having multiplayer being written in Rust really helped! By refactoring the code to isolate ownership of the file into an encapsulated type, it was easy to audit all cases where the file gets updated and ensure that the corresponding payload was written to the journal and the sequence number was incremented. Additionally, we were able to provide self-serve read access to the underlying file type without granting mutable access. If other devs at Figma who lack context want to access the file mutably without writing to the journal, they’d have to ignore a very-well documented file and reviews from the code owners.
Validating the journal
We’ve refactored, audited the logic, and wrote tests. Still, how can we be sure that we’ve covered all the edge cases in the millions of Figma files that exist out in the wild? To build more confidence, we ran validations against real-world data. If we have a file at checkpoint A, make some changes, and end up with checkpoint B, we should be able to check that re-creating checkpoint B from checkpoint A and from all the entries between checkpoints A and B results in a byte-by-byte identical file blob. These validations were run asynchronously on a fraction of checkpoints during a dark-launch period where changes were only written to the journal and not read from the journal.
After ~400K consecutive successful validations, we started rolling out the feature to a fraction of the files, eventually reaching 100% rollout after careful monitoring. Today the journal handles >2.2B received changes per day, persists 95% of changes within ~600ms, and has helped prevent a number of incidents from causing data loss! The journal is also a key part in several teams’ on-call handbooks for investigating and debugging tricky edge-case errors.
Looking ahead
What’s next for the journal? There are a number of things we’re excited to follow up on in the future.
Faster load times
We can use the journal to speed up file load times. When clients load the file, they can skip re-downloading the file if they have it locally with the same sequence number as what’s loaded by multiplayer. But if the file has changed on the server, the client has to re-download the file. Now that we have a journal, we can download some number of entries from before the checkpoint and use them to catch clients up to the current state of the file without having to send the entire file over.
Avoiding checkpoints
Now that we have the journal, we’re no longer limited to use checkpoints for other services that want to read the current state of the file. For example, we have a public API endpoint that renders the file to an image. If the endpoint is called while the file is being edited, multiplayer needs to create a checkpoint in order for the image rendering service to get the current state of the file for rendering. This adds significant latency when the checkpoint needs to be created (for the worst 5% of files, creating a checkpoint can take ~4 seconds or more). In the future we’ll be able to leverage the journal to avoid checkpointing in these cases, which will reduce load on multiplayer and improve latency.
File data across Figma
We can build a self-service platform to allow other internal teams to subscribe to and use the journal data. We have a similar system for listening to updates for metadata stored in the database (powered by the Postgres replication log) that powers a number of services in Figma. There are a number of interesting features we could power with the journal: file webhooks, activity graphs, time-lapse, etc.
Multiplayer is one of the core aspects of Figma, and makes real-time collaboration a reality for teams around the globe. We’re constantly looking to improve the multiplayer experience for users and continuing to build trust with our community of creators who need a reliable and stable platform to do their best work. If this kind of work interests you, we’re hiring!