GraphQL, meet LiveGraph: a real-time data system at scale





Software Engineers Rudi Chen and Slava Kim shares an inside look at how we empower engineers to build real-time data views, while abstracting the complexity of pushing data back and forth.
Share GraphQL, meet LiveGraph: a real-time data system at scale
The magic of Figma products is that real-time collaboration across teammates and locations feels effortless. From a product perspective, this means that the data we fetch and display to the user needs to be real-time, too. For example, if a user is looking at files for their latest project and a coworker adds a new file to the project, the new file needs to show up for them right away, without needing to refresh the page.
For the infrastructure team, the question was: how do we empower our product engineers to build these real-time views easily, while abstracting away the complexity of pushing data back and forth?
To provide a general solution to this fundamental business need, we developed LiveGraph, a data fetching layer on top of Postgres that allows our frontend code to request real-time data subscriptions expressed with GraphQL. It issues queries directly to the database and provides live updates in the order of milliseconds by reading the database replication stream.
Challenges, in real-time
Since 2016, Figma has used React for the frontend, which fetches data from Ruby HTTP endpoints. At first, each page load would fetch all the data it needed in a single large request, then put it in global state using Redux. To provide real-time updates, product engineers would manually craft event messages to be sent to the relevant clients everywhere we write to the database in our backend code. Then, the frontend would need to subscribe to these event messages using a WebSocket connection and apply the update to the global state.
For a long time, this approach served us well and allowed us to move fast and develop new product features quickly. However, as each user's usage of Figma grew, so did the amount of data each client was requesting on page load. Naturally, we started splitting up the request and loading data incrementally. But, this adds complexity, and we couldn’t guarantee that all data would be available in-memory at all times. When multiple product areas needed the same data, it created confusion regarding who is responsible for fetching the data and when the data is guaranteed to be available.
In addition to the usage growth, new product features further increased the complexity of maintaining client state using ad hoc notifications. While certain types of events are quite straightforward (e.g. “a new file was created”), others could be much more complicated. For example, a change in the value of a resource affecting permissions could have a large downstream effect in the visibility of other resources. It also wasn’t possible to guarantee that real-time messages would be sent or received in the same order as the corresponding write to the database. Overall, working with them became hard to reason about and caused a lot of data consistency bugs in which the client state no longer reflected the subset of server state it was supposed to.
In-house vs. out-of-the-box
We realized that we needed a more general framework that would allow product developers to declaratively define data subscriptions. A natural choice for this interface was to use GraphQL, which would allow the system to automatically fetch and keep the data live-updated. We decided to build it in-house and call it LiveGraph.
There are many systems that offer similar functionality. For example, even within Figma, we have a service called multiplayer (which we wrote about here A peek into the homegrown solution we built as the first design tool with live collaborative editing.How Figma’s multiplayer technology works
Since Figma already operates at scale using Postgres, LiveGraph needed to be a data-fetching layer built on top of our existing infrastructure. In other words, it had to be a query engine, not a persistence layer. As a result, we couldn’t migrate to real-time databases such as Firebase or RethinkDB just for the sake of better live data.
Next, we took a look at the GraphQL ecosystem, since that was the interface that we wanted to expose. Many GraphQL-related technologies have features tied to data subscriptions. Note that the terminology in the industry around real-time data subscriptions can be confusing: GraphQL has a concept of subscriptions, but is used to subscribe to event streams, more akin to our old system with hand-crafted events. Instead, we wanted what is sometimes referred to as “Live Queries” in GraphQL-world.
However, the key motivation for LiveGraph wasn’t to migrate Figma to using GraphQL, but to provide a robust and highly scalable system for live data. Technologies like Hasura, Prisma, and PostGraphile all offer subscription capabilities, but not with subscription scalability built as a primary use case. In some cases, they explicitly advise against large volumes of concurrent subscriptions.
Specifically, we wanted to avoid polling-based solutions to providing live data, which multiply the load on the database beyond what we were comfortable with. It also forces application developers to decide on the polling frequency on a per-query level. A key LiveGraph design decision is to tail the database replication log, which also provides faster update latency than polling. Since this means that LiveGraph will need to read the full volume of database updates, it's also important that our solution has a path towards distributing updates from multiple database shards across multiple machines.
Ultimately, we decided to invest in LiveGraph as an in-house solution. Due to Figma's collaborative nature, LiveGraph is core to our business and a potential competitive advantage. Our claim is not that LiveGraph is strictly better than alternatives, but instead that our needs are specific enough that the investment made sense to us.
LiveGraph on the frontend
From a product developer’s perspective, LiveGraph provides an API that receives GraphQL-like queries and sends back the result as a JSON tree.
Like other GraphQL backends, we have a schema that describes the server-side entities/relations that make up our object graph, and views that allow querying a subset of that graph.
type File {
key: string
name: string
comments: [Comment] @filter("Comment.key=File.key AND Comment.deletedAt=null")
}
type Comment {
id: bigint
message: string
userId: bigint
author: User @filter("User.id=Comment.userId")
}query FileWithComments($fileKey: String!) {
file(fileKey: $fileKey) {
name
comments {
id
message
author {
id
name
}
}
}
}The client will typically make queries in React using a call to a custom hook useSubscription:
function CommentsUI(props: { fileKey: string }) {
// useSubscription(name of the view, arguments)
const comments = useSubscription(FileWithComments, { fileKey })
if (comments.status === 'loading') {
return <Spinner />
} else {
return <CommentsList comments={comments.data} />
}
}To support this, LiveGraph consists of both a server and a client-side library. The useSubscription hook is part of the client-side library, which will send a request to the server. The client will then receive a response as a series of JSON messages that the library uses to reconstruct the result and its follow-up updates. This result object is statically-typed, as LiveGraph is capable of generating TypeScript bindings for the GraphQL API. It will then be passed as props to further React components for rendering.
The key is that this React component will always render the latest data from the server without any additional work. No more custom event streams per feature! Under the hood, the client library receives incremental updates to the result and constructs a new tree made of in-memory references. The useSubscription hook then triggers a re-render of the component. In other words, the usage of the hook alone makes the component real-time.
In addition, the interface provides consistency guarantees on notification delivery. Updates are guaranteed to be received in order and exactly once. If the client ever disconnects, the library will reconnect under the hood and refetch the data for the view.
LiveGraph also offers the ability to define access control rules on objects, and on relations between objects. This way, the server will not send the client any instances of data that fail the permission checks. Furthermore, these permission checks can themselves be dependent upon data loaded from subscribed subviews, allowing the permissions to be updated in real-time, as well.
Finally, the LiveGraph frontend library also includes APIs for optimistic updates. This allows updating the front-end state with a user edit before the server write goes through, eliminating latency in the user experience. By integrating this feature within LiveGraph, we can detect when the subscription updates with the result of the write and automatically remove the now-redundant optimistic update.
LiveGraph on the backend
By abstracting the complexity of real-time updates away from the client, the challenge is now on the backend: understanding how to efficiently route changes from the database to the appropriate clients.
One of the key requirements when designing LiveGraph was to make sure that the migration of product features to LiveGraph does not cause drastic load increases on the database. While real-time updates are top of mind, guaranteeing high website availability is even more important.
Without this constraint, we might use polling as a simple architecture for providing real-time data—at regular intervals, we could refetch the entire view. However, this would multiply the amount of queries issued to the database by a large factor. Instead, we subscribe to the database replication stream (write-ahead log), which is distributed across servers via Kafka.

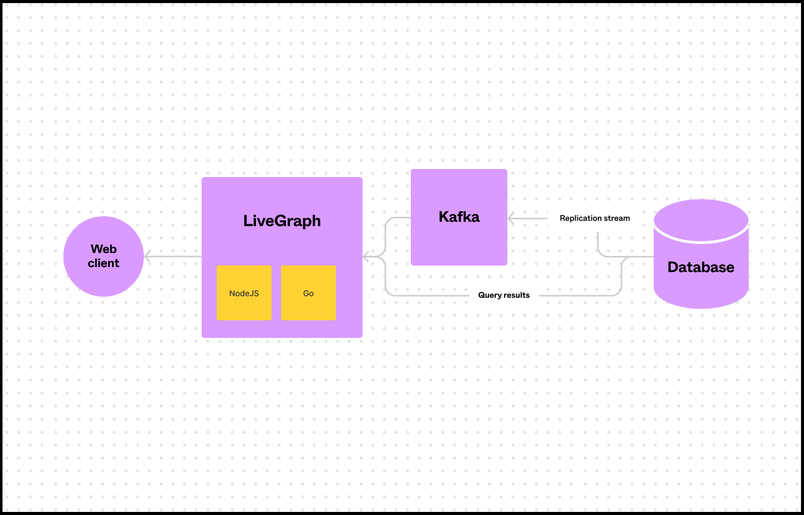
The bookkeeping for each view subscription is handled by decomposing the view into a tree of more granular subqueries. A view fetches many types of data, but a subquery fetches a single type of object. Translated into SQL, these subqueries take the form SELECT columns FROM table WHERE condition without any joins. The conditions represent the relation between objects which was defined in the schema. LiveGraph maintains an in-memory tree representation of the view (the live view tree) where each node in the tree is a subquery.
With this decomposition, we can subscribe each subquery separately. Using the filter condition of each subquery, we maintain an index of all active subqueries for each type of object. This way, we can efficiently route each new entry in the replication stream to update the cached result of the appropriate subqueries. In turn, this updates the corresponding live view tree(s).
One benefit of this decomposition is that we can deduplicate a lot of work by sharing subqueries between live view trees, effectively creating a caching layer. For example, in a large organization, you could have thousands of users loading the file browser, all of which will contain the subquery SELECT id, name FROM teams WHERE org_id = x which fetches the data needed to populate the list of teams in the sidebar. Since subscribing to a query implies that we keep the result set in memory after the initial request to the database, subsequent subscriptions to the same query will reuse the latest result set, all within LiveGraph.
LiveGraph is implemented using a combination of both NodeJS and Go. The JavaScript part exists to share code with the client. The naive way to send updates to the client would be to send a JSON serialization of the entire view result every time it updates, but that would be inefficient. So, the client is actually isomorphic with the server—it uses the same live view tree bookkeeping code to maintain its subscription. However, for the areas in the backend that are lower-level and more performance-intensive, we use Go for its multithreading capabilities and (generally) faster performance.
Present and future work
In order for LiveGraph to be a dependable service in a high-traffic production environment, we need to solve many challenges. The most obvious one is that LiveGraph needs to be designed to scale, as Figma scales. This means that it needs to support a sharded database. Currently, each instance can process the entire database replication stream to provide updates, which is on the order of 10,000 writes/second. In a sharded world, the updates come from multiple database streams, which affects consistency guarantees. Eventually, the write load will also exceed what a single LiveGraph instance can handle, meaning that LiveGraph itself will need to be sharded, such that each shard only reads a subset of the streams.
Scaling horizontally will also allow LiveGraph to spread out the CPU and memory load of supporting subscriptions. However, even then, we must be careful about spikes in load, both on individual instances (e.g. large views) and across the fleet. A particular aspect of scaling that creeps up in production is thundering herd. Since the client maintains persistent WebSocket connections with the server, mass reconnections after a deploy cause a large number of views to be re-subscribed at once. As such, it's insufficient to look at steady-state load—specific events such as deploys can cause service degradation.
In addition to scaling challenges, LiveGraph is more than just a service—it’s a change in how we fetch data at Figma. It is not solely an infrastructure effort, but an engineering-wide adoption workstream. On the product side, we are:
- Adopting LiveGraph throughout the codebase while working to ensure we introduce no regressions in the process. We already power key products such as the mobile apps, comments, and the prototyping and editor views, and hope to extend this to any feature that benefits from real-time updates.
- Working with product teams to support or refactor existing product use cases that are non-trivial to directly translate into GraphQL.
- Creating tools and workflows so that it’s easy to evolve and version our schema.
- Identifying the best React architecture and best practices when using data from view subscriptions.
- Implementing pagination, a challenging problem in the face of real-time update, to support unbounded views.
Some of these problems are similar to those that organizations encounter while migrating from REST to GraphQL, but the subscription aspect always adds a unique flavor to each of these challenges. By solving them, we're facilitating the development of real-time features that define what makes Figma so unique.
Of course, this work is happening inside of a fast-growing startup! Every week, we encounter new scaling challenges. We are constantly learning about more product needs as our usage grows and product expands. It would be difficult to point to a precise milestone or moment in time where we would consider LiveGraph to be “done.” This is a natural consequence of designing a system to solve real problems for real users, and it’s exactly what makes the work fun. If this sounds equally interesting to you, Figma is hiring—join us!
Thank you to the Asana team for consulting with us on LunaDB during LiveGraph’s development.