



Postmortem: Service disruptions on June 6 & 7 2022




The root cause of our recent service outage and how we resolved it.
Share Postmortem: Service disruptions on June 6 & 7 2022
A number of people experienced issues using Figma at different points in time between 11:34 PM PDT, June 6, 2022 and 10:43 AM PDT June 7, 2022. During this window, there were 4 incidents of service disruption ranging from 7 minutes to 1 hour and 20 minutes. The incidents stopped re-occurring at 10:41AM PDT, at which point the web application was fully functional, but our web API still had some functionality disabled. We re-enabled all remaining functionality later that day.
During the four impacted time frames, files that were already loaded continued to work, but it wasn’t possible for users to open new files or collaborate with others. There was no data loss caused by this incident. Changes that were made to files during the periods of instability were saved locally and stored on our servers each time the service came back online.
This was the longest period of instability Figma has ever experienced. We take downtime extremely seriously, and we are deeply sorry for the disruption it caused.
Now that the dust has settled and we’re confident we’ve resolved the issue, we want to share more details about what happened, how we resolved it, and the steps we’re taking to prevent it from happening again.
TL;DR: What happened?
We were alerted to the incident by our monitoring system within seconds of the service disruption. The team quickly honed in on the key problem—we were using up 100% of the Engine CPU of a Cluster-Mode Enabled ElastiCache node.

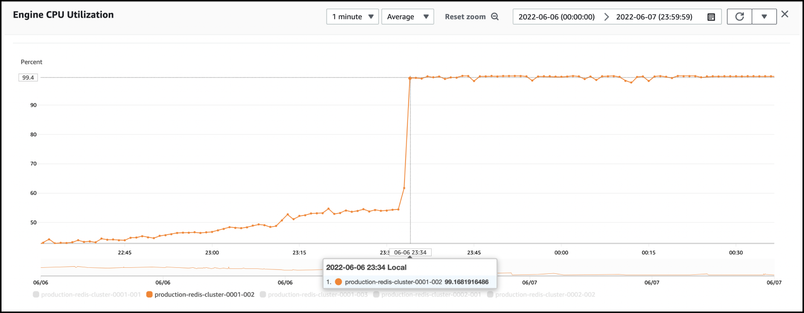
We use a managed service from AWS called ElastiCache. At its core, ElastiCache leverages Redis, an open-source, in-memory data store that supports fast read and write operations. We use ElastiCache to accelerate frequently accessed data and route messages between some of our services.
ElastiCache automates many of the operations that go into running Redis. At the time of the incidents, we were running two instances of ElastiCache—one with Cluster-Mode Enabled (CME) and another with Cluster-Mode Disabled (CMD). CME provides horizontal scaling by allowing new Redis nodes to be added dynamically.
The service disruptions were caused by sudden saturation of the Engine CPU of one of the nodes in the Cluster-Mode Enabled ElastiCache instance. After extensive investigation, AWS found that this Engine CPU saturation occurred because of a rare bug which is triggered when a client runs a high Redis Publish / Subscribe load on a Cluster-Mode Enabled (CME) ElastiCache for Redis cluster. AWS is working to improve performance of Redis Publish / Subscribe on CME clusters.
We have been using Publish / Subscribe operations with ElastiCache for many years without any issues. A few weeks ago, we shifted our Publish / Subscribe load to our ElastiCache instance with Cluster-mode Enabled from an instance with Cluster-mode Disabled. The Cluster-Mode Enabled instance was able to support this use case for a few weeks without any issues, and there weren’t any notable changes in our traffic patterns or usage of Redis in the days leading up to the incidents.
When the first service disruption occurred, it was very difficult for us to isolate the root cause because we don’t have the ability to obtain CPU profiles from the underlying machines that run ElastiCache to see exactly what is consuming CPU time. Despite this, we knew we had to take immediate action and mitigate the impact while we waited for the ElastiCache service team to respond.
How did we resolve it?
We suspected either a capacity issue or a bad machine. To mitigate the risk of bad hardware, we initiated a failover of the impacted node. In parallel, we spun up a new ElastiCache instance with a larger node type and a higher number of nodes to ensure we had more capacity if needed. The node failover did not complete as quickly as expected, so we ended up redirecting traffic to the new ElastiCache clusters (V2) instead, and Figma recovered. It wasn’t until much later that we learned that increasing the size of the cluster actually made things worse.
Throughout this time, the team was working to identify the root cause of the incident. We were investigating and ruling out the following hypotheses:
- A routine backup or unexpected snapshot temporarily overloaded the node. There was no sign of this.
- A sudden increase in Redis command usage. Command usage was smooth and consistent with previous weeks.
- Problematic Redis usage. We looked at slow commands, big keys, etc., but could not locate a smoking gun. Many commands were taking longer after the incident started, but none were taking longer just prior to the incident. We expect commands to take longer when the CPU is pegged.

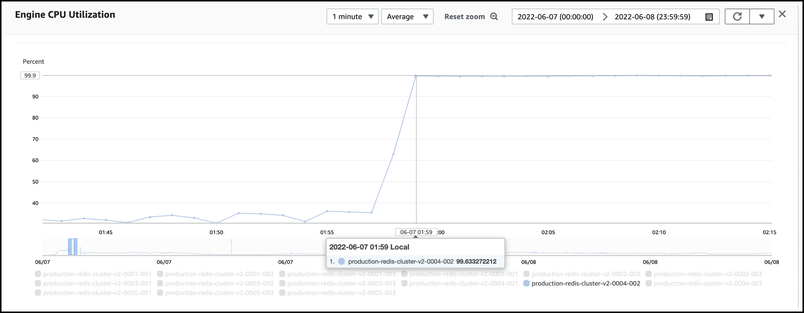
While we investigated, we hit the same issue again at 1:59 AM PDT, even as our peak traffic load was subsiding. We initiated a failover of the impacted node again. This time the failover worked as intended, and we were able to recover the service more quickly. This gave us the time and space to continue our investigation. Still, our strongest hypothesis was that there was some kind of problematic Redis usage. We black-holed some of the requests that appeared to be waiting the longest for Redis commands to complete, but it didn’t help. In parallel, we looked through the list of scheduled background jobs that ran prior to each incident to understand if there was a pattern—a job that might be triggering problematic behavior in Redis. We weren’t able to uncover any notable patterns and continued our investigation.

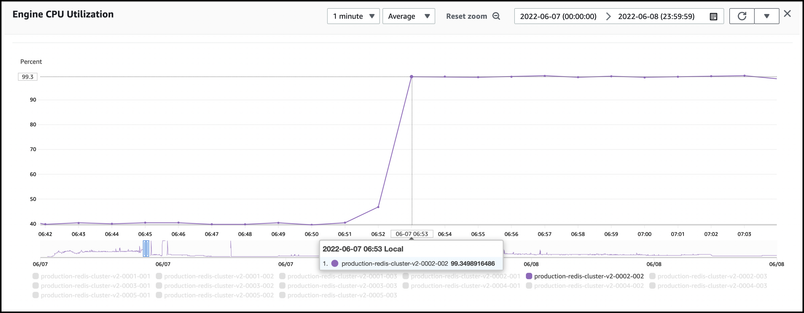
We hit the same issue again at 6:53 AM PDT, as Figma usage started to pick back up as the East coast of North America came back online. This enabled us to rule out the functionality we had already disabled as a potential source of the issue. We again initiated a failover, which worked as intended, and the service recovered quickly again. We disabled more non-core functionality to further isolate the problem.
The issue occurred one last time at 9:36 AM PDT. This time, we were unable to initiate a failover because we had exceeded a rate limit on the number of manual failovers a customer can perform on an AWS ElastiCache cluster in a given period of time. We asked AWS to raise the limit and started work to migrate to a new cluster (V3) in the event they were unable to do so. By the time AWS raised the limit, we had already redirected traffic over to a new Redis cluster (V3).
The silver lining of all of this is that the V2 cluster was no longer serving core production traffic but continued to be pegged at 100% CPU. This gave us a test environment to disable more functionality without having to worry about impacting users. There were a small set of services that were still talking to the cluster. We disabled them one-by-one and observed the impact each time. This helped us localize the source of the issue to a small set of Redis usages. We suspected the Publish / Subscribe usages might be the problem but didn’t yet have enough data to know for sure.
Knowing this new information, we began isolating these workloads from core product functionality. While we were working on isolating more services, we left these workloads disabled. Fortunately, the user impact of this decision was relatively small.
After partitioning our original Redis cluster into multiple separate clusters, we systematically spread out our Redis usage across them. The team meticulously rolled out the changes in our Staging environment first before making changes in the Production environment. We then rolled the changes into our Production environment and restored all remaining Redis workloads.
As we approached 11:35 PM PDT, exactly 24 hours since the incidents started, we braced ourselves for another period of peak utilization. Fortunately, our efforts worked, and we did not see another occurrence of the same issue.
The following morning, June 8th, AWS’s ElastiCache service team completed their investigation and pinpointed the problem to a bug they had recently discovered with Publish / Subscribe workloads in Clustered ElastiCache instances. They shared this information with our team on a call, and we immediately set out to move all our Publish / Subscribe workloads off of Clustered ElastiCache, which we completed that same afternoon.
The Redis Cluster-Mode Enabled Bug
We’ve been working with the AWS ElastiCache service team for the last week to verify the bug and understand the conditions that triggered it.
The open source version of Redis with Cluster Mode enabled uses a module called a Cluster Bus to communicate with other nodes in the same Redis Cluster instance. This Cluster Bus was originally designed as a control plane communication layer, meaning it was meant to be used as a mechanism to coordinate amongst the cluster Nodes via smaller, less frequent system messages.
As this comment in the Redis source code states, it was not optimized for handling client data messages, which can be much larger and more frequent. The Publish / Subscribe commands are some of the only data plane commands that leverage the Cluster Bus to exchange client data with other nodes in a Redis Cluster. Other data plane commands use a more efficient mechanism for communicating directly with individual nodes.
The Cluster Bus maintains a buffer on each Redis node for outgoing messages to all other nodes in the Cluster. This buffer starts out small, and grows as needed to store more messages in the event that it can’t send messages quickly enough to all other nodes. The buffer growth is exponential because of the way it does pre-allocation to reserve additional room each time the buffer grows.
This type of exponential growth will occur if the frequency or size of messages going through the Cluster Bus exceeds the rate at which the Cluster Bus can send data to ALL other nodes in the cluster. Growth will also occur if there are network issues communicating with ANY node in the cluster, even if the frequency and size of the message remains constant.
The growth of the Cluster Bus buffer is not a problem in itself. The key issue is the way the Cluster Bus buffer keeps track of what is left to send to each client. Each time the Cluster Bus sends a little data to a client, it tracks how many bytes were sent and truncates the buffer accordingly. It does this truncation via an internal Redis function called sdsrange, which itself uses the system function memmove to shift all remaining data in the buffer to the head of the buffer.
The memmove function takes CPU time that is proportionate to the amount of memory being moved. So if the Cluster Bus sends 100KB to a client, and there is 10GB of additional data to send, the memmove function will need to process nearly 10GB of data to truncate the buffer each time it sends a message. When AWS helped us reproduce the incident, they were able to see that most of the Engine CPU time was going to memmove in the sdsrange call stack. Because the Cluster Bus buffer grows exponentially, it’s very easy for the CPU time in memmove to escalate extremely quickly.
During the incident, we saw no evidence of a significant change in the number of messages we were publishing. What likely happened is a network event or issue on one of the other nodes in the cluster caused messages to be sent in smaller chunks and more slowly, leading to more buffer growth and memmove operations. As the buffer grew exponentially, the memove operation to truncate the buffer became increasingly expensive, slowing down the rate that the buffer could send messages to other nodes, and therefore leading to even more exponential buffer growth. Due to the design of this buffer, this process is self-reinforcing, meaning it can get more and more expensive to send messages, even if the original condition that triggered the growth goes away. This is why the Redis Engine CPU stayed at 100% for so long disrupting the Figma service.
Due to other enhancements AWS has made to their managed Redis service, the problem is a bit worse on ElastiCache than it is in Open Source Redis, but it’s not much better in the Open Source Redis. As a result, we suggest other teams avoid using Publish / Subscribe commands on all Redis instances with Cluster Mode Enabled until the bug is resolved.
In Summary
The incident was caused by a bug in AWS's ElastiCache service with Cluster Mode enabled. The bug is such that high Publish / Subscribe workloads can trigger a sudden and sustained spike in Engine CPU utilization. Due to the complex nature of this bug, we did not hit it for weeks despite having moved our Publish / Subscribe workfloads to a Clustered-Mode Enabled Redis instance much earlier.
After the first occurrence of the incident at 11:30 PM PDT on June 6, we failed over to a new ElastiCache cluster with more capacity. Unfortunately, this new capacity meant there were more nodes for the Cluster Bus to coordinate, and this decreased the threshold of Publish / Subscribe usage that is required to trigger the bug. As a result, the incident occurred more frequently after the failover until we had successfully isolated the Publish / Subscribe workload onto its own Redis Instance.
We believe we are no longer susceptible to this bug because we have moved all our Publish / Subscribe workloads back to an AWS ElastiCache instance with Cluster mode Disabled.
Next Steps
We are confident that our new setup—where major use cases of ElastiCache use different ElastiCache instances—gives us better isolation and finer-grained control over our ability to selectively disable features in an emergency. It also improves our visibility into significant changes in the traffic and performance characteristics of these use cases.
We learned a lot from the incident and are already taking steps to improve our resilience to such incidents in the future. These include:
- Ensuring that the core user workflows in Figma are even more resilient to unexpected ElastiCache failures
- Introducing more ways to easily enable / disable non-core functionality for Figma during unexpected failures
- Running Disaster Recovery Training (DRTs) exercises at regular intervals to verify core functionality works when ElastiCache is unavailable
- Improving the behavior of our internal libraries for communicating with ElastiCache instances
- Reviewing our incident response plans with AWS to understand how we can work together better with their service teams to pinpoint AWS service bugs faster
Building a reliable and highly available service for users is our top priority. We will continue to find ways to make that experience seamless and share our learnings along the way.
If you have any questions about this incident, please don’t hesitate to get in touch at support@figma.com.