



A deep dive on deep search




We recently rolled out deep search to help you find the right file even faster. Here, the team who built it gives you a behind-the-scenes look at the technical challenges they faced and the tradeoffs they made along the way.
Share A deep dive on deep search
A few months ago we launched Universal Search Today, we’re announcing Universal Search and Links in the editor. Read on for more on these new features.

Look no further: New ways to search and provide context in Figma
When you think back on a project, specific file and folder names probably aren’t top of mind. Instead, you might remember an idea, a snippet of copy, or the problem you solved. Now, with deep search you can find what you’re looking for without knowing the name of the file—type in a keyword, and Figma will return all files that contain that word or phrase.
Here, we’re giving you an inside look into how deep search came to life—a glimpse into our infrastructure, the technical challenges we faced along the way, and the team who made it happen.
Building in the browser
We’ve previously shared the technical infrastructure Scaling infrastructure at a fast-growth startup

Under the hood of Figma’s infrastructure: Here’s what goes into powering a web-based design tool
These features often translate to better collaboration. Being in the browser allows for streamlined prototyping and handoff, and stakeholders can easily check in on a project without waiting for an exported file. It encourages sharing in-progress work, which ultimately makes the end result better.
From a product perspective, when we think about which features to build, our roadmap is informed by the benefits that come with being built on the web. Figma has the ability to provide really rich information about all the files you have access to. We can show you how often your components are being used, how frequently your files are viewed, and dig deep into the structure of your file. That’s why deep search felt like the natural next step in bringing added context to your files.
The technical foundation
Late last year, we launched Design System Analytics Design System Analytics enables you to see library usage trends, compare libraries, and drill into component usage.

Opening up the data behind your design systems
Both Design System Analytics and deep search required a system that opens a recently edited file, pulls it down from storage and walks through the file to retrieve relevant information. For Design System Analytics, the information was about shared library usage; for deep search, it’s the text within your files.
Bringing deep search to life
While Design System Analytics laid the technical foundation, we still needed to generalize the service. This required unpacking what sets deep search apart.
What makes deep search different
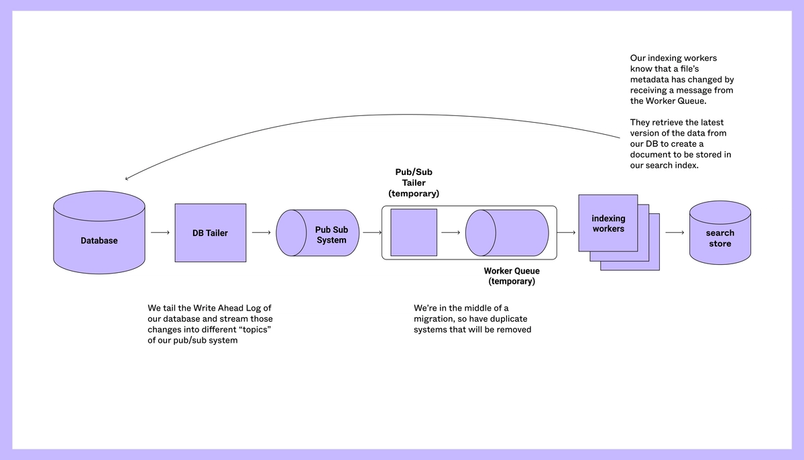
In all our previous updates to search, including those released by Unified Search, we only had to deal with metadata stored in our database—items like the title of your file and its creator. For our regular search, our data pipeline is similar to search in other tools. We tail relevant tables in our database and stream the IDs of changed items into a messaging system. From there, our search indexers retrieve messages, get the most up to date information from our database and then index that into our elasticsearch cluster.

{
"id": 123,
"folder_id": 28,
"team_id": 456,
"name": "File",
"folder_name": "Drafts",
}Deep search is a different beast. While our regular search indexers gather a file’s metadata such as its key or team id from the database, the representation of our Fig files (our internal name for Figma files) is stored as a .fig document type in Amazon S3. The Fig file can be thought of as a tree, where a node represents a Figma object like an ellipsis, frame, vector, or some text. Each node also contains an object’s properties.
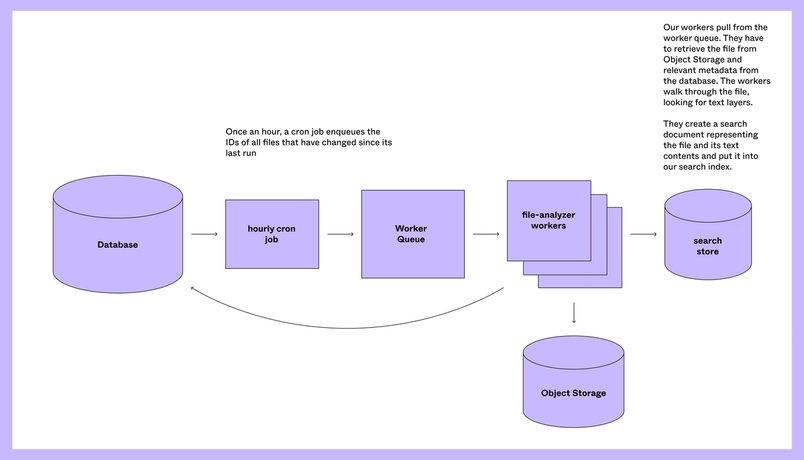
Making tradeoffs
While it’s fairly cheap to retrieve things from our database, retrieving a Fig file and then walking through it is extremely computationally expensive because they may have thousands of nodes. It would be expensive to make changes to our deep search index at the same cadence as our regular search index—as you edit your file, a new save is made for you every 30 seconds. Instead, we deduplicate all file changes every hour and send those files off to be processed by our file-analyzer workers—the platform we built for DSA which helps handle computationally intensive, periodic tasks. We made the product decision to allow deep search results to be stale for a short amount of time to save our servers a significant amount of duplicated work.

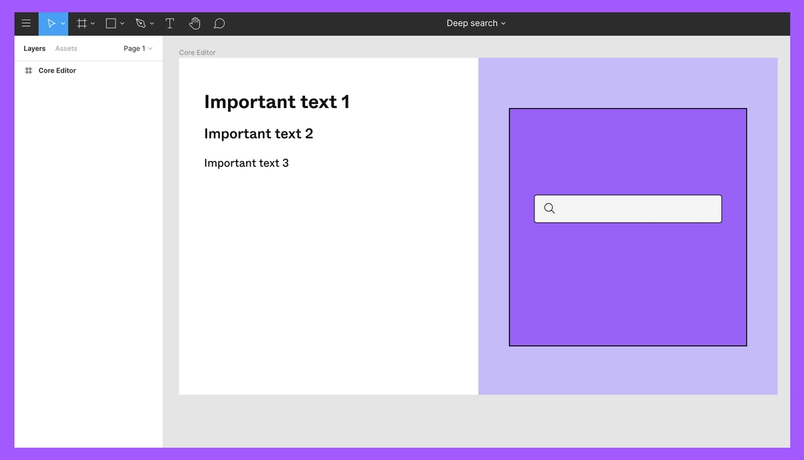
Let’s say we have a file that contains five relevant nodes: a frame, rectangle and three text nodes. Our file-analyzer workers walk through each node and retrieve a text node’s contents, disregarding all other nodes types. The file-analyzer passes that data to the deep search indexer, which then stores the text in a multi-value elasticsearch field labeled text_instances.

{
"id": 123,
"folder_id": 28,
"team_id": 456,
"text_instances": [
"Important Text 1",
"Important Text 2",
"Important Text 3",
]
}
The file-analyzer stores the three text nodes in the text_instances field
There was a lot of discussion over what should and shouldn’t be stored in our deep search index. Should instances count, or only components? Do we care about page names and layers or just text? Here, search is more art than science. It’s not immediately clear what would improve search accuracy and what would just be plain noise. To tease out the intricacies, we implemented different versions of deep search to try for ourselves.
From our hands-on approach, we learned a lot about how users interact with Figma. For example, it turns out that page names—for the most part—are more generic than the contents of your page; page names are relatively short and tend to be categorical rather than unique to the file. A common pattern we found was page names being used to show the progression of the designs: “Idea”, “Rough draft”, “Final.” Searching through page names gives the average user less signal than the content in their page, as they’d apply the same naming scheme for the pages across all their Fig files.
We also made the call that instances of components matter. There was much debate around this particular discussion—since instances are copies of a main component, leaving them out meant that we could de-duplicate a ton of text, greatly reducing the size of our deep search index. Storage nowadays is relatively cheap, but it’s not free. We ultimately decided that not only do components matter, but also the frequency of components in your Fig file matter too. If you add an instance with the text “Figma is cool” into a file 100 times, this should rank higher in your search results for “Figma is cool” than a file that only has this string once.
At the end of the day, search is a living, breathing, developing product. We’re learning as we go about what users are looking for and how, and applying this information to make a better product going forward.
The team behind deep search
While deep search required coordination across teams, the working group was relatively small, allowing us to move quickly. I (Shloak, here!) recently joined Figma full-time, but I worked on deep search while I was an intern on our infrastructure team. I started with an infrastructure-side investigation before partnering closely with Stella, an engineer on our collaboration team, to productize the work.
Stella oversaw the roll out of our dark and live launches, and brought in our infrastructure and data science partners to ensure the project would be a success. Lizhi, another engineer on infrastructure, was instrumental in making sure file search remained performant. It was incredible to work with such a great team on unique technical problems as an intern, and one of the reasons I chose to return to Figma.
As we continue thinking about the ways designers collaborate with people across teams, we’ll look to specific workflows, like developer handoff. If this sounds like the type of project you’d be excited to dive into, come build with us—we’re hiring! You can check out more about Figma and our open roles here.

