The growing pains of database architecture




How the Figma infrastructure team reduced potential instability by scaling to multiple databases.
Share The growing pains of database architecture
In 2020, Figma’s infrastructure hit some growing pains due to a combination of new features, preparing to launch a second product, and more users (database traffic grows approximately 3x annually). We knew that the infrastructure that supported Figma in the early years wouldn’t be able to scale to meet our demands. We were still using a single, large Amazon RDS database to persist most of our metadata—like permissions, file information, and comments—and while it seamlessly handled many of our core collaborative features, one machine has its limits. Most visibly, we observed upwards of 65% CPU utilization during peak traffic due to the volume of queries serviced by one database. Database latencies become increasingly unpredictable as usage edges closer to the limit, affecting core user experiences.
If our database became completely saturated, Figma would stop working.
We were far from that, but as an infrastructure team, our goal is to identify and fix scalability issues proactively before they come close to being imminent threats. We needed to devise a solution that would reduce potential instability and pave the way for future scale. Plus, performance and reliability would continue to be top of mind as we implemented that solution; our team aims to build a sustainable platform that allows engineers to rapidly iterate on Figma’s products without impacting the user experience. If Figma’s infrastructure is a series of roads, we can’t just shut down the highways while we work on them.
We started with a few tactical fixes to secure an additional year of runway, while we set the foundation for a more comprehensive approach:
A read replica is a copy of the primary instance that reflects changes to the primary in almost real time, in normal circumstances.
PgBouncer is a lightweight connection pooler for PostgreSQL.
- Upgrade our database to the largest instance available (from r5.12xlarge to r5.24xlarge) to maximize CPU utilization runway
- Create multiple read replicas to scale read traffic
- Establish new databases for new use cases to limit growth on original database
- Add PgBouncer as a connection pooler to limit the impact of a growing number of connections (which were in the thousands)

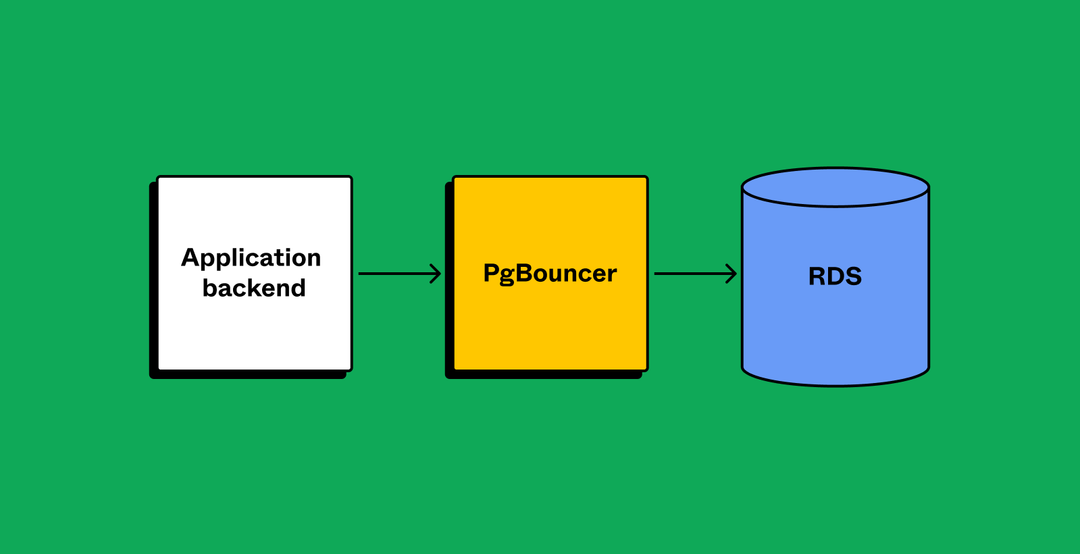
While these fixes moved the needle, they had limitations. By analyzing our database traffic, we learned that writes— like gathering, updating, or deleting data—contributed to a significant portion of database utilization. Additionally, not all reads or data fetching could be moved to replicas due to application sensitivity to replication lag. So, from both a read and write perspective, we still needed to offload more work from our original database. It was time to move away from incremental changes and look for a longer-term solution.
Exploring our options
We first explored options for horizontally scaling our database. Many popular managed solutions are not natively compatible with Postgres, the database management system we use at Figma. If we decided on a horizontally scalable database, we would either have to find a Postgres-compatible managed solution, or self-host.
Migrating to NoSQL databases or Vitess (MySQL) would require a complex double read and write migration, and NoSQL in particular would also warrant significant application-side changes. For Postgres-compatible NewSQL, we would’ve had one of the largest single-cluster footprints for cloud-managed distributed Postgres. We didn’t want to bear the burden of being the first customer to hit certain scaling issues; we have little control over managed solutions, so relying on them without a stress test at our level of scale would expose us to more risk. If not a managed solution, our other option was self-hosting. But since we had relied on managed solutions to date, there would be significant upfront work to acquire the training, knowledge, and skills our team would need to support self-hosting. It would mean a large operational cost, which would take away from our focus on scalability—a more existential problem.
Vertical partitioning is when a database is split by moving tables and/or columns into a separate database.
After deciding against both paths forward for horizontally sharding, we had to pivot. Rather than horizontally shard, we decided to vertically partition the database by table(s). Instead of splitting each table across many databases, we would move groups of tables onto their own databases. This proved to have both short- and long-term benefits: Vertical partitioning relieves our original database now, while providing a path forward for horizontally sharding subsets of our tables in the future.
Our approach to partitioning
Before we could begin the process, however, we first had to identify tables to partition into their own database. There were two important factors:
- Impact: Moving the tables should move a significant portion of workload
- Isolation: The tables should not be strongly connected to other tables
To measure impact, we looked at average active sessions (AAS) for queries, which describes the average number of active threads dedicated to a given query at a certain point in time. We calculated this information by querying pg_stat_activity in 10 millisecond intervals to identify CPU waits associated with a query, and then aggregated the information by table name.
Each table’s degree of “isolation” proved core to whether it would be easy to partition. When we move tables into a different database, we lose important functionality such as atomic transactions between tables, foreign key validations, and joins. As a result, moving tables can have a high cost with respect to how much of the Figma application has to be rewritten by developers. We had to be strategic by focusing on identifying query patterns and tables that were easy to partition.
This proved to be difficult with our backend tech stack. We use Ruby for the application backend, which services the majority of our web requests. Those, in turn, generate most of our database queries. Our developers use ActiveRecord to write these queries. Due to the dynamic nature of Ruby and ActiveRecord, it’s hard to determine which physical tables are affected by ActiveRecord queries with static code analysis alone. As a first step, we created runtime validators that hooked into ActiveRecord. These validators sent production query and transaction information (such as caller location and tables involved) into Snowflake, our data warehouse in the cloud. We used this information to look for queries and transactions that consistently referenced the same group of tables. If these workloads turned out to be costly, those tables would be identified as prime candidates for vertical partitioning.
Managing migration
Once we identified which tables to partition, we had to come up with a plan for migrating them between databases. While this is simple when performed offline, going offline isn’t an option for Figma—Figma needs to be up and performant at all times to support users’ real-time collaboration. We needed to coordinate the data movement across thousands of application backend instances, so they could route queries to the new database at the correct moment. This would allow us to partition the database without using maintenance windows, or downtime, for each operation, which would be disruptive for our users (and also require off-hour work from engineers!). We wanted a solution that met the following goals:
- Limit potential availability impact to <1 minute
- Automate the procedure so it is easily repeatable
- Have the ability to undo a recent partition
We couldn’t find a pre-built solution that met our requirements, and we also wanted the flexibility to adapt the solution for future use cases. There was only one option: build our own.
Our bespoke solution
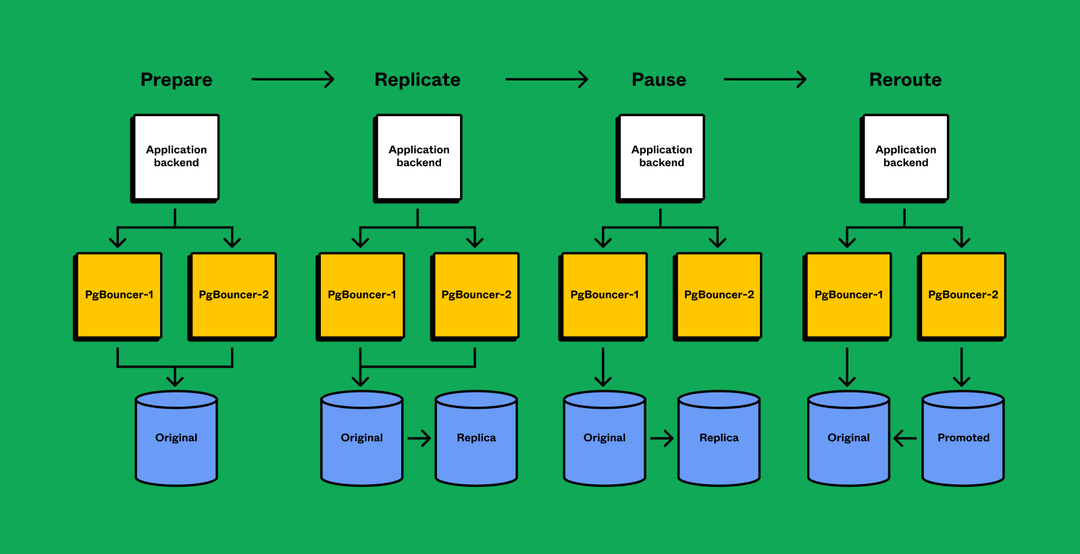
At a high level, we implemented the following operation (steps 3–6 complete within seconds for minimal downtime):
- Prepare client applications to query from multiple database partitions
- Replicate tables from original database to a new database until replication lag is near 0
- Pause activity on original database
- Wait for databases to synchronize
- Reroute query traffic to the new database
- Resume activity
Preparing client applications correctly was a significant concern, and the complex nature of our application backends made us anxious. What if we missed an edge case that broke after partitioning? To de-risk the operation, we leveraged the PgBouncer layer to gain runtime visibility and confidence that our applications were configured correctly. After partnering with product teams to make the application compatible with partitioned databases, we created separate PgBouncer services to virtually split traffic. Security groups ensured that only PgBouncers could directly access the database, meaning client applications were always connected via PgBouncer. Partitioning the PgBouncer layer first would give clients leeway to route queries incorrectly. We’d be able to detect the routing mismatch, but since both PgBouncers have the same target database, the client would still successfully query data.

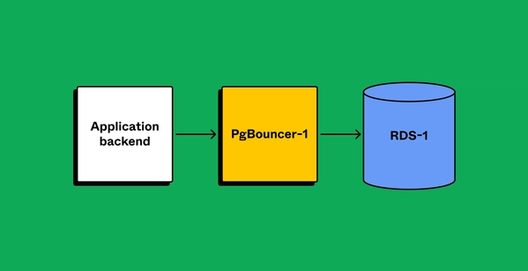

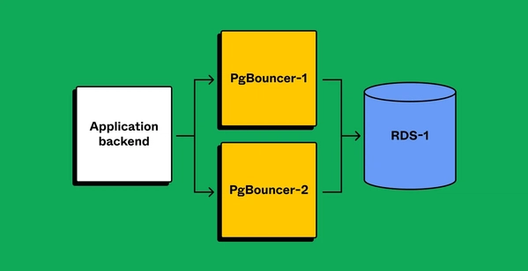

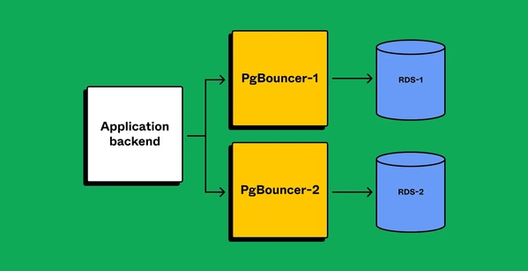
Once we verified that applications are prepared with separate connections for each PgBouncer (and sending traffic appropriately), we’d proceed.
The “logical” choice
In Postgres, there are two ways to replicate data: streaming replication or logical replication. We chose logical replication because it allows us to:
- Port over a subset of tables, so we can start with a much smaller storage footprint in the destination database (reduced storage hardware footprint can increase reliability).
- Replicate to a database, which is running a different Postgres major version, meaning we can perform minimal-downtime major version upgrades with this tooling. AWS has blue/green deployment for major version upgrades, but the feature is not yet available for RDS Postgres.
- Set up reverse replication, which allows us to roll back the operation.
The main issue with using logical replication is that we’re working with terabytes of production data, so the initial data copy could require days, if not weeks, to complete. We wanted to avoid this to not only minimize the window for replication failure, but also the cost of restarting. We considered carefully coordinating a snapshot restore and starting replication at the correct point, but a restore eliminated the possibility of having a smaller storage footprint. Instead we decided to investigate why logical replication’s performance is so sluggish. We discovered that the slow copy is a result of how Postgres maintains indexes in the destination database. While logical replication copies rows in bulk, it inefficiently updates indexes one row at a time. By removing indexes in the destination database and rebuilding the indexes after the initial copying of data, we reduced the copy time to a matter of hours.
Via logical replication, we were able to build a reverse replication stream from the newly partitioned database and back to the original. This replication stream was activated just after the original database stopped receiving traffic (more on this below). Modifications to the new database would be replicated back to the old database, and the old database would have these updates in the event we rolled back.
The critical steps
With replication solved, we found ourselves at the crucial steps of coordinating query rerouting. Every day, thousands of client services query the database at any given time. Coordinating across this many client nodes is prone to failure. By performing our sharding operation in two phases (partitioning PgBouncers, then data), the critical operation of partitioning data would only require coordination across a handful of PgBouncer nodes serving the partitioned tables.
Here’s an overview of the ongoing operation: We coordinate across nodes to stop all relevant database traffic only briefly in order for logical replication to synchronize the new database. (PgBouncer conveniently supports pausing new connections and rerouting.) While PgBouncer pauses new connections, we revoke clients’ query privileges on the partitioned tables in the original database. After a brief grace period, we cancel any remaining in flight queries. Since our application mostly issues short duration queries, we typically cancel a little under 10 queries. At this point, with traffic paused, we then need to verify our databases are the same.
Ensuring that two databases are the same before rerouting clients is a fundamental requirement for preventing data loss. We used LSNs to determine if two databases were synchronized. If we sample an LSN from our original database once we’re confident that there are no new writes, we can then wait for the replica to replay past this LSN. At this point, the data is identical in both the original and the replica.

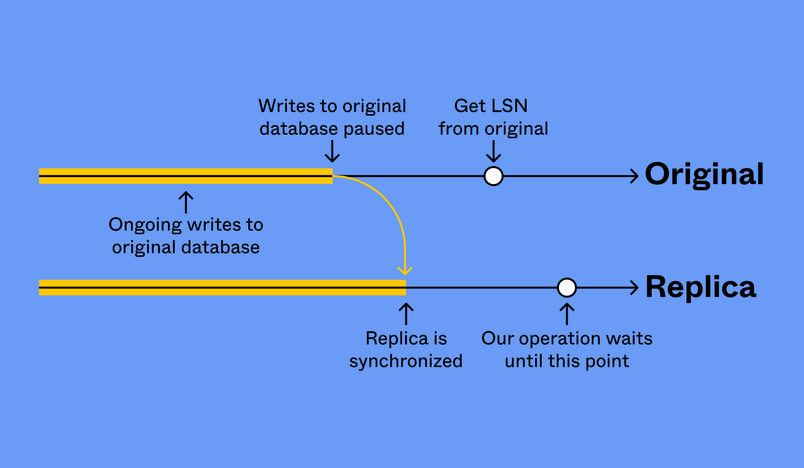
After we’ve checked that the replica is synchronized, we stop replication and promote the replica to a new database. Reverse replication is set up as previously mentioned. Then, we resume traffic in PgBouncer, but now the queries are routed to the new database.

Planning for our horizontal future
We’ve since successfully performed the partitioning operation many times in production, and each time, we met our initial objective: address scalability without impacting reliability. Our first operation involved moving two high-traffic tables, while our final operation in October 2022 involved 50. During each operation, we observed a ~30 second period of partial availability impact (~2% of requests dropped). Today, each database partition is operating with greatly increased headroom. Our largest partition has CPU utilization hovering ~10%, and we’ve decreased the resources allocated to some of the lower traffic partitions.
And yet, our work here is not done. Now with many databases, client applications have to maintain knowledge of each one, and the routing complexity scales multiplicatively as we add more databases and clients. We’ve since introduced a new query routing service which will centralize and simplify routing logic as we scale to more partitions. Some of our tables have high write traffic or billions of rows and terabytes of disk footprint, and these tables will hit disk utilization, CPU, and I/O bottlenecks individually. We always knew that if we only relied on vertical partitioning, we’d eventually reach scaling limits. Going back to our aim of maximizing leverage, the tooling we created for vertical partitioning will make us better equipped to horizontally shard tables with high write traffic. It has provided us with enough runway to tackle our current projects and keep Figma’s “highways” open, while also seeing around the bend.
Stay tuned for more details on these projects. Scaling our database architecture is both a complex and exciting task that is essential for Figma’s success. If you’re interested in working on projects like this, we’re hiring!
Nothing great is made alone, and the following database team members were instrumental in bringing this workstream to life: David Harju, Dylan Visher, Erica Kong, Gordon Yoon, Josh Bancroft, Kevin Lin, Langston Dziko, Ping-Min Lin, Rafael Chacon Vivas, Roman Hernandez, Sammy Steele, and Yiming Li.
I'd also like to thank all of our cross-functional partner teams, and especially the following individuals: Jared Wong, Josh Tabak, Karl Jiang, Kevin Stewart, Kyle Hardgrave, Michael Harris, Ricky Zein, Shloak Jain, Tommy MacWillliam, William Li.
Tim Liang is a Software Engineer at Figma, where he works on the databases team.