



Inside Figma: a case study on strict null checks


A look at how we identify and address bugs in a systematic way, through the lens of a recent sprint.
Share Inside Figma: a case study on strict null checks
At Figma, we believe in continuously investing in product quality and developer productivity by looking at recurring types of bugs and addressing them in a systematic way. A few months ago, our engineering team completed a large effort that achieves both: turning on the strictNullChecks compiler flag for our front-end TypeScript codebase.
Code written with strict null checks operates under different type-checking rules and has a markedly different flavor than code written without. Converting our codebase to use it was a large undertaking that we think serves as an interesting case study in code migration.
In this blog post, we’d like to share how we performed this migration incrementally without slowing down concurrent product development.
What are strict null checks?
In many popular typed programming languages (e.g. TypeScript, Java, etc), most or all variables are allowed to have the value null, indicating the absence of a more specific value.
// strictNullChecks: off
interface Vector { x: number, y: number }
var v: Vector = { x: 1, y: 2 } // ✅ This is allowed
v = null // ✅ This is also allowed
function length(v: Vector) {
// We may need to check for nullity when we're not sure.
if (v) {
return Math.sqrt(v.x * v.x + v.y * v.y)
} else {
// Return some default value?
// What does it even mean to call length(null)?
}
}Most of us are used to this. However, this is not a fundamental property of programming languages. It was an intentional design choice by Tony Hoare back in 1965, who would later call it his billion dollar mistake.
And there are actually languages that do it differently, enforcing compile-time rules that ensure a value can be null only if explicitly declared nullable. Examples include Rust, OCaml, Haskell, and C# as of version 8.0. TypeScript programs can opt-in to stricter compile time null checking using the strictNullChecks compiler option. When this option is enabled, TypeScript performs control flow analysis to ensure the code does not use a value that might be null in unsafe ways.
// strictNullChecks: on
interface Vector { x: number, y: number }
var vector: Vector = { x: 1, y: 2 } // ✅ This is allowed
vector = null // ❌ Error! `vector` cannot be null
// ✅ These are allowed
var nullableVector: Vector | null = { x: 1, y: 2 }
nullableVector = null
function length(v: Vector) {
// ✅ Compiler guarantees that this is safe
return Math.sqrt(v.x * v.x + v.y * v.y)
}
// Clearly indicates that `null` is a supported argument
function someHelperFunction(v: Vector | null): number {
console.log(v.x) // ❌ Compilation error! v could be null
if (v) {
// ✅ Inside this block, v has type `Vector`,
// not `Vector | null` because the if statement
// eliminated the `| null` case. TypeScript is smart!
return length(v)
} else {
return defaultValue
}
}By enabling strict null checks, we can eliminate an entire class of errors (e.g. cannot access .name of undefined). In non-strict code, this is of the most common types of error, and our historical data shows that a few of our high-severity incidents would have been caught by strict null checks before landing on production.
Strict null checks also improve the quality of code. Maintaining code involves asking questions about the code such as “is file info loaded at this point in the code?” Expressed in the type system, these questions often boil down to “can this value be null?” When the answer is right in the type, the code is much more maintainable.
Incrementally enabling strict null checks
Although today the TypeScript community recommends starting new projects with strict null checks enabled, Figma started using TypeScript prior to TypeScript 2.0, when strict null checks were first implemented. Even after upgrading, we wrote new code that didn’t necessarily compile with the setting enabled. Our situation wasn’t unique: JavaScript codebases where types have been added incrementally also often don’t have strict null checks enabled, because JavaScript is inherently non-strict.
Migrating such codebases to strict null checks is challenging. Merely turning it on can generate thousands of errors. When we started the project, our frontend codebase of ~1162 TypeScript files generated over 4000 errors, and in many cases fixing one of them would reveal even more errors. It was clear that while this migration was not nearly as drastic as a full rewrite in a different architecture or language, it would require a similar thinking process. Here’s a few ways one might do it:
Stop-the-world
We could have asked all our engineers to stop working on their current project to participate in the migration.
We didn’t feel this was the right decision: the work involved in migrating is parallelizable but not that parallelizable, so having everyone stop their work was not an optimal use of time. It would also have been strategically questionable, as our product work at the time was critical to maintaining business momentum. Finally, the logistics of coordinating between multiple teams becomes less practical the larger companies get.
Whack-a-mole
Another approach is to fix errors from enabling strict null checks over time, without actually enabling strict null checks (e.g. running them only during CI).
This is the least disruptive approach. The downside is that without strict null checks enforced, new code tends to introduce new errors. At startups that grow exponentially, that can be a lot of new code: during the time it took us to complete the migration, our codebase increased from 376k to 464k lines of code. A “whack-a-mole” strategy can still be reasonable if errors can be fixed faster than they are introduced, but having a “progress bar” that even occasionally moves backward is not fun.
Progressive allowlist
The approach we’ve taken is to strict null check one file at a time by adding them to an allowlist.
Before talking about the details of this approach, we’d like to give credit where it’s due! We were inspired by the VS Code team’s effort to strict null check, a codebase similar in size to ours. We started from the tooling they built, then extended it to better solve problems unique to our codebase.
The core of this approach is to compile the codebase twice: once for all files without strict null checks enabled, and once for a list of files that are known to compile successfully with strict null checks enabled.
// tsconfig.strictNullChecks.json
{
"extends": "./tsconfig.json",
"compilerOptions": {
"strictNullChecks": true
},
"files": [
... add files here ...
],
}A key observation is that compiling a TypeScript file requires compiling all its dependencies (imports). That means that unlike some other more lint-like flags like --noImplicitAny, it makes sense to strict null check a file only if its dependencies are also strict. Therefore, a file can be added to the allowlist only after its dependencies are in the allowlist. Knowing that, here’s the process of adding files to the allowlist:
- We start with the codebase as an acyclic tree where the nodes are files and the edges are dependencies (we’ll talk about cycles later):

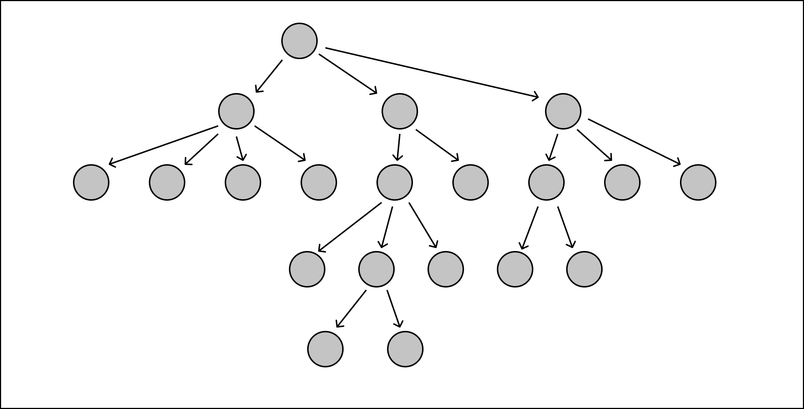
- List all the files that are currently candidates for strict null checking. These are the files whose dependencies are all already on the allowlist. We wrote a script to generate a list of these candidates. To gauge the impact of converting a candidate to strict null checks, the list is sorted by the number of files that depend on the candidate.
- [ ] `"./figma_app/lib/library_helpers.ts"` — Depended on by >**158** files (23 direct imports)
- [ ] `"./figma_app/reducers/org_user_test.ts"` — Depended on by >**127** files (18 direct imports)
- [ ] `"./figma_app/reducers/picker.ts"` — Depended on by >**84** files (18 direct imports)
- [ ] `"./figma_app/views/fullscreen/multilevel_dropdown/multilevel_dropdown.tsx"` — Depended on by >**83** files (8 direct imports)
- [ ] `"./shared/auth/internal/auth_middleware.ts"` — Depended on by >**55** files (4 direct imports)
...
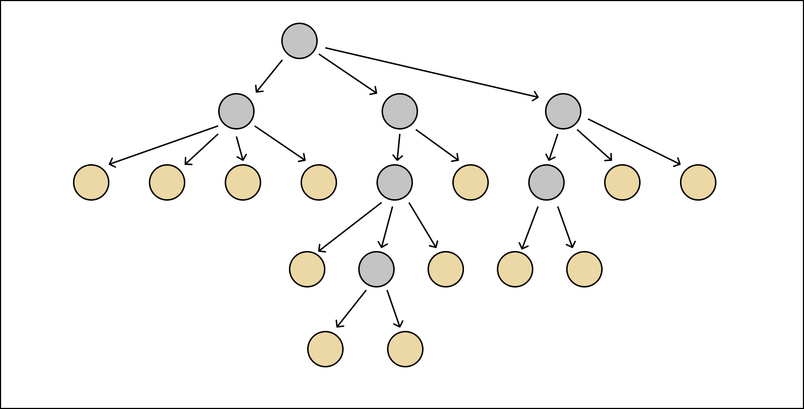
- Pick a candidate file and add it to the
files: []section oftsconfig.strictNullChecks.json. Run TypeScript, and fix any new compilation errors. - Once some files have been added to the allowlist, new files will become eligible as candidates.

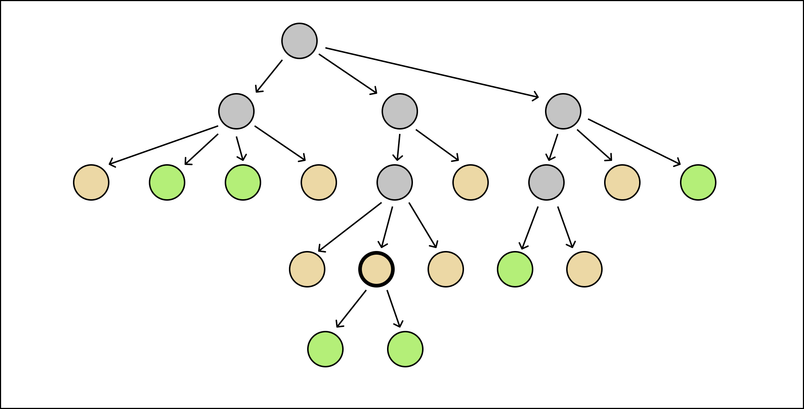
- Repeat until the whole tree is green.
- Turn on
--strictNullCheckseverywhere!
For our actual codebase, we made a dependency graph visualizer, which was very helpful both for planning ahead (identifying files to prioritize) and visualizing our progress. It looks something like this:


Next, let’s look at some details around the execution of this strategy.
Dealing with quirks of our codebase
We’ve open-sourced the tools we used here. It’s a set of scripts that use the TypeScript Compiler API for dependency analysis, which we found pleasantly easy to use. We started off with what the VS Code team had built, then adapted it for our codebase.
First, we had to deal with quirks in our codebase that get in the way of static analysis. For example, the tooling had trouble resolving barrel imports, a TypeScript feature that allows bundling together exports from multiple different files. We used this in only a handful of places, and it was simplest both for the migration and the codebase simply to remove them.
A major addition to the tooling was the ability to deal with dependency cycles, which were common in our codebase at the start of the project. Dependency cycles made it more difficult to perform the migration incrementally: it’s not possible to add a single file in a cycle to the allowlist unless you add all of the files in the cycle simultaneously. In terms of the dependency graph, we had to treat each cycle as a strongly-connected component, which effectively becomes a single node in the dependency graph.

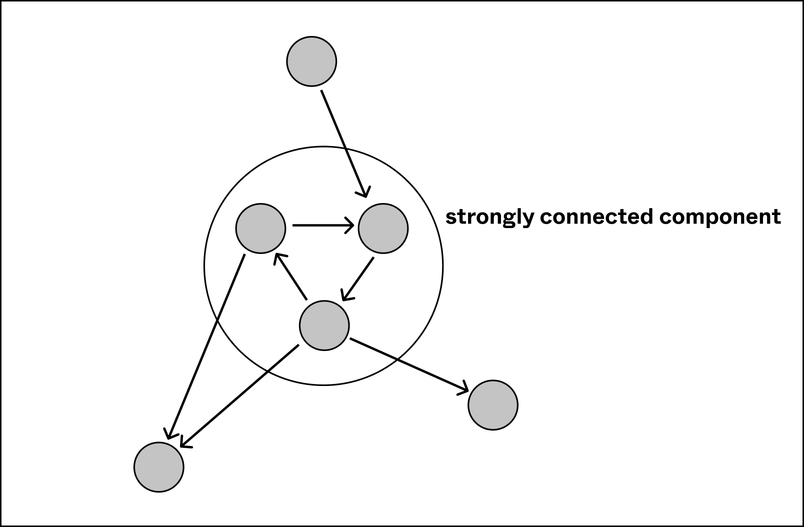
The largest cycle we had was a 500+ file monstrosity — almost half our codebase! In addition to unblocking the strict null check migration, breaking up this monolith would also improve the architecture of the codebase. To do so, we targeted common patterns that were causing cyclic dependencies. For example:
- Figma uses Redux, so we have models, actions and reducers. We had previously been defining the models in the same file as the reducers. By moving models into their own file, the action file no longer needed to import from the reducer file, breaking the cycle.
- All the modals in our UI were in the same cycle. They were all imported by the modal renderer in
modal.ts, but each modal also imported constants frommodal.ts. Moving the constants to its own file broke the cycle.
Fixing these root issues reduced the size of the cycle by hundreds of files. Merging them was challenging because they touched hundreds of files and often conflicted with other people’s commits. In one case, we used jscodeshift to automate the refactor, which made it easier to rebase & re-generate the entire refactor on top of the latest master.
The migration
The initial phase of “scouting out” the landscape — setting up tooling and removing blockers like cycles — was done by a small group of engineers. After that point, the codebase was well set up for the whole team to contribute. We hosted two three-day sprints where members from different teams across Figma contributed to strict null checking files, particularly in their areas of expertise. All in all, 30 engineers contributed to the effort at various points in time. This was a good way to get more people involved, without being disruptive to other teams.
Execution policy
An important aspect of this migration was to establish guidance around how much effort to spend migrating each individual file. While some errors can be fixed just by changing a type annotation, many others require refactoring the code to prove nullability (or lack thereof).
For example, consider this common way of using a stack, which will fail to compile under strict null checks:
// stack: Array<number>
if (stack.length > 0) {
const v = stack.pop() // type: number | undefined
console.log(v + 1) // error: Object is possibly undefined
}It is clearly correct by inspection, but requires either a non-null assertion ! or rewriting it differently:
const v = stack.pop()
if (v != null) {
console.log(v + 1) // ✅
}Which then led the question: should we tell the team to just avoid refactoring while migrating, or to refactor whenever possible?
To avoid refactoring, a lot of type annotation needed to be made nullable by adding | null whenever it’s hard to prove that a value can’t be null. This, in turns, requires adding a lot of non-null assertions or a lot of if-statements. The former still leaves the code vulnerable to errors. The latter can be misleading to future readers when the if-statements turn out to be redundant. Either way, it makes the type annotations hard to trust, which reduces the value of strict null checks.
On the other hand, refactoring while migrating can make the whole process take much longer. It often requires the engineer not only to understand the code, but the corresponding product area to understand if nullability is intended. It also risks causing regressions.
At Figma, we encouraged the team to refactor when possible. We believed the additional investment was worth it to make sure our type annotations could be trusted by future maintainers. While the migration did introduce a few regressions, our engineers are full-time employees and were around to fix them. Finally, we posit that if code broke during migration, it must have already been hard to reason about (with respect to nullability) and would likely be regressing later.
But the “when possible” part is important too. At the end of the day, the goal was to complete the migration, and being in a partially-migrated state has downsides — having two instances of the compiler eating up the CPU being one of many. So while we recommended refactoring, we also opted to give the team a lot of discretion and let people take shortcuts when it would take too long to do otherwise.
Of course, the tradeoff will vary by situation. For example, in an open-source project with volunteer contributors, or in a system with a lot of legacy code, it may be a lot more troublesome to deal with regressions.
Once a majority of files passed strict null checks, the remaining work became less parallelizable. At that point, we switched from an allowlist to a denylist approach, using the exclude option instead of files, so that new files are automatically compiled under strict mode. At this point, a few engineers were able to convert the remaining files and complete the project.
Parting thoughts
In terms of catching errors, we can say that null errors no longer show up in our error dashboard. However, we would like to re-emphasize: the biggest benefit, though hard to measure, is probably the increased readability of our code. The parts of the code where TypeScript has the most trouble inferring nullability were often the ones that were hard for humans to reason about — and benefited the most from refactoring.
With all that said, this migration wasn’t a straight path to the target. There were periods of time with very little activity where everyone (including the drivers of the project) were busy with other tasks. Fortunately, the benefit of an incremental approach is precisely that it provides flexibility in planning. Being able to make small progress in the beginning was helpful in building momentum, and then finally complete the migration.
So while most of you might not need to do this exact migration, we hope this has served as a useful example of large-scale code changes!
If this type of work sounds interesting to you, learn more about the team and Figma — we’re hiring!
Rudi Chen is a Software Engineer, and was previously on the infrastructure team at Figma.



